正确阅读代码,词法分析器助你一臂之力
由 Mux 主办的 DEV 全球展示挑战赛:展示你的项目!

软件的核心在于逻辑。编程一直以来都被认为是一个充斥着数学和复杂公式的领域。而计算机科学似乎正是这种误解的根源所在。
当然,编程中确实会用到一些数学和公式——但我们根本不需要拥有微积分博士学位才能理解机器的工作原理!事实上,我们在编写代码的过程中学到的许多规则和范式,也同样适用于复杂的计算机科学概念。有时,这些概念本身就源于计算机 科学,只是我们之前从未意识到而已。
无论我们使用哪种编程语言,大多数人在编写代码时都会将不同的功能封装到类、对象或方法中,有意地将代码的不同部分所关注的功能区分开来。换句话说,我们知道将代码拆分成一个类、对象或方法,使其只负责单一功能,通常是有益的。如果我们不这样做,代码可能会变得非常混乱,相互交织,最终形成一张错综复杂的网。即使遵循了关注点分离原则,这种情况有时仍然会发生。
事实证明,就连我们计算机的内部运作也遵循着非常相似的设计范式。例如,我们的编译器由不同的部分组成,每个部分负责处理编译过程中的特定环节。上周我们学习解析器时就略有体会,解析器负责创建语法树。但解析器不可能承担所有任务。
解析器需要它的伙伴们的帮助,现在终于到了我们了解它们是谁的时候了!
逐步集成到编译器中
最近学习解析的时候,我们浅尝辄止地接触了语法、句法以及编译器在编程语言中如何处理这些概念。但我们从未真正深入探讨过编译器究竟是什么!随着我们深入了解编译过程的内部运作,我们将学习很多关于编译器设计的知识,因此,理解我们在这里讨论的内容至关重要。
编译器听起来可能有点吓人,但实际上它们的工作原理并不复杂——特别是当我们把编译器的各个部分分解成易于理解的小部分时。
但首先,让我们从最简单的定义开始。编译器是一个程序,它读取我们的代码(或任何编程语言的任何代码),并将其翻译成另一种语言。

一般来说,编译器的作用仅仅是将高级语言代码翻译成低级语言。编译器翻译成的低级语言通常被称为汇编代码、机器代码或目标代码。值得一提的是,大多数程序员实际上并不直接处理或编写机器代码;相反,我们依赖编译器将程序翻译成机器代码,最终计算机才能运行这种可执行程序。
我们可以将编译器视为我们程序员和计算机之间的中间人,计算机只能运行用低级语言编写的可执行程序。
编译器负责将我们想要发生的事情翻译成机器能够理解和执行的方式。
如果没有编译器,我们就只能通过编写机器代码与计算机通信,而机器代码极其难以阅读和解读。机器代码在人眼看来通常只是一堆 0 和 1——记住,它都是二进制代码——这使得它极难阅读、编写和调试。编译器为我们程序员抽象化了机器代码,因为它让我们无需考虑机器代码,而是可以使用更加优雅、清晰、易读的语言来编写程序。
接下来几周,我们将继续深入剖析这个神秘的编译器,希望这能逐渐揭开它的神秘面纱。但现在,让我们回到最初的问题:编译器最简单的组成部分是什么?
无论编译器的设计如何,它都包含不同的阶段。正是这些阶段让我们能够区分编译器的各个独特部分。

我们最近学习了解析器和解析树,已经接触到了编译过程中的一个阶段。我们知道,解析是指接收输入并构建解析树的过程,有时也简称为解析行为。实际上,解析工作是编译过程中一个称为语法分析的阶段。
然而,解析器并非凭空构建解析树。它需要一些帮助!我们还记得,解析器会收到一些词法单元(也称为终结符),并根据这些词法单元构建解析树。但是,这些词法单元从何而来呢?幸运的是,解析器不必孤立地工作;相反,它得到了一些帮助。
这就引出了编译过程的另一个阶段,即语法分析阶段之前的一个阶段:词法分析阶段。

“词汇”一词指的是脱离其所在句子语境,单独分析一个词的含义。如果我们仅根据这个定义来推测词义,可能会认为词汇分析阶段只关注程序中单个词语/术语本身,而与语法或包含这些词语的句子的含义无关。
词汇分析阶段是编译过程的第一步。它不了解也不关心句子的语法或文本或程序的含义;它只了解词语本身的含义。
在解析源程序中的任何代码之前,必须先进行词法分析。在解析器能够读取程序之前,程序必须先经过扫描、拆分和分组等特定方式的处理。
上周我们开始学习句法分析阶段时,了解到句法分析树是通过分析句子的各个组成部分,并将表达式分解成更简单的部分而构建的。但在词法分析阶段,编译器并不知道或无法访问这些“组成部分”。相反,它必须先识别并找到这些组成部分,然后再将文本拆分成各个部分。
例如,当我们读到莎士比亚的句子“To sleep, perchance to dream.”时,我们知道空格和标点符号将句子的“单词”分隔开来。这当然是因为我们已经接受过训练,能够阅读句子、进行词义分析并分析其语法。
但是,对于编译器来说,同样的句子第一次读取时可能看起来像这样:Tosleepperhachancetodream。当我们阅读这句话时,很难确定其中的“单词”究竟是什么!我相信编译器也有同样的感受。
那么,我们的机器是如何处理这个问题的呢?嗯,在编译过程的词法分析阶段,它总是会做两件重要的事情:扫描代码,然后对代码进行求值。

扫描和求值工作有时可以合并到一个程序中,有时也可以是两个相互依赖的独立程序;这实际上取决于编译器的具体设计方式。编译器中负责执行扫描和求值工作的程序通常被称为词法分析器或标记器,而整个词法分析阶段有时被称为词法分析或标记化过程。
扫描,或许会读到
词法分析的两个核心步骤中,第一步是扫描。我们可以把扫描理解为实际“读取”输入文本的过程。请记住,输入文本可以是字符串、句子、表达式,甚至是整个程序!这其实并不重要,因为在这个阶段,它只是一大段字符,没有任何意义,而且是一个连续的文本块。
让我们来看一个例子,了解具体是如何发生的。我们使用最初的句子“To sleep, perchance to dream.”,这就是我们的源文本或源代码。对于编译器来说,这段源文本会被读取为类似“Tosleep,perchancetodream.”的输入文本,这只是一串尚未被解码的字符。

编译器首先要做的就是将那一大段文本分割成尽可能小的部分,这样就能更容易地确定那一大段文本中单词的实际位置。
将一大段文本分割成小块的最简单方法就是缓慢而有条不紊地逐个字符地阅读。而这正是编译器所做的。
通常情况下,扫描过程由一个名为扫描器的独立程序处理,它的唯一任务就是逐个字符地读取源文件/文本。对于我们的扫描器来说,文本的大小并不重要;它“读取”文件时一次只会看到一个字符。
我们的扫描仪会将莎士比亚的这句话解读成这样:

我们会注意到,“To sleep, perchance to dream.”已被扫描器拆分成单个字符。此外,单词之间的空格以及句子中的标点符号也被视为字符。序列末尾还有一个特别有趣的字符:eof。这是“文件结束符”,类似于制表符、空格和换行符。由于源文本只有一个句子,当扫描器到达文件末尾(在本例中为句子末尾)时,它会读取文件结束符并将其视为一个字符。
实际上,当我们的扫描器读取输入文本时,它将其解释为单个字符,结果如下:["T", "o", 空格, "s", "l", "e", "e", "p", ",", 空格, "p", "e", "r", "c", "h", "a", "n", "c", "e", 空格, "t", "o", 空格, "d", "r", "e", "a", "m", ".", eof]。

现在我们的扫描器已经读取并将源文本拆分成最小的部分,它将更容易识别句子中的“单词”。
接下来,扫描器需要按顺序查看拆分后的字符,并确定哪些字符是单词的一部分,哪些不是。对于扫描器读取的每个字符,它都会标记该字符在源文本中所在的行号和位置。
图中所示为处理莎士比亚句子的过程。我们可以看到,扫描器会标记句子中每个字符所在的行和列。我们可以将行和列的表示形式想象成一个字符矩阵或数组。
请记住,由于我们的文件只有一行,所以所有内容都位于第 0 行。但是,随着我们处理句子,每个字符所在的列都会递增。另外值得一提的是,由于我们的扫描器会将空格、换行符、文件结束符和所有标点符号都视为字符,因此它们也会出现在字符表中!

源文本扫描并标记完成后,我们的编译器就可以将这些字符转换成单词了。由于扫描器不仅知道文件中空格、换行符和文件结束符的位置,还知道它们相对于周围字符的位置关系,因此它可以扫描所有字符,并根据需要将它们分割成单独的字符串。
在我们的示例中,扫描器会先扫描字符 T,然后是 o,最后是一个空格。当它遇到空格时,会将 To 拆分成一个单词——即在遇到空格之前最简单的字符组合。
对于它找到的下一个单词“sleep”,情况也类似。然而,在这种情况下,它先读出“sleep”,然后读出一个逗号(,),一个标点符号。由于这个逗号两侧分别有一个字符(p)和一个空格,因此逗号本身也被视为一个“单词”。
单词“sleep”和标点符号“.”都被称为词素,它们是源文本的子字符串。词素是源代码中最小的字符序列组合。源文件的词素被视为文件本身的单个“单词”。扫描器读取完文件中的单个字符后,会返回一组类似这样的词素:["To", "sleep", ","", "perchance", "to", "dream", "."]。

请注意,我们的扫描器如何将一段文本作为输入(最初无法读取),然后逐个字符地进行扫描,同时读取并标记其内容。之后,它利用字符间的空格和标点符号作为分隔符,将字符串分割成最小的词素。
然而,尽管做了这么多工作,在词汇分析阶段的这个阶段,我们的扫描器对这些词仍然一无所知。没错,它确实把文本分割成了不同形状和大小的词,但至于这些词到底是什么,扫描器却一无所知!这些词可能是一个字面字符串,也可能是一个标点符号,或者完全是其他的东西!
扫描器对单词本身一无所知,也不知道它们是哪种“单词类型”。它只知道单词在文本中的起始和结束位置。
这就为词汇分析的第二阶段——评估——做好了准备。扫描文本并将源代码分解成单个词素单元后,我们必须评估扫描器返回的单词,并确定我们正在处理的单词类型——特别是,我们必须寻找在我们试图编译的语言中具有特殊含义的重要单词。
评估重要部分
完成源文本扫描并识别词素后,我们需要对这些词素“词”进行处理。这就是词汇分析的评估步骤,在编译器设计中通常被称为词法分析或分词过程。

当我们评估扫描后的代码时,实际上就是仔细检查扫描器生成的每个词素。编译器需要查看每个词素,并判断它属于哪种类型的词。编译器正是通过确定文本中每个“词”的词素类型,将每个词素转换成一个词元,从而对输入字符串进行词元化。
我们最早接触到词法单元(token)是在学习语法分析树的时候。词法单元是每种编程语言的核心,它们是特殊的符号。诸如括号 (,)、加号 (+)、减号 (-)、if、else、then 等词法单元,都能帮助编译器理解表达式的不同部分以及各种元素之间的关系。语法分析器是语法分析阶段的核心,它依赖于从某个地方接收词法单元,然后将这些词法单元转换成语法分析树。

猜猜怎么着?我们终于找到“某个地方”了!原来,发送到解析器的词元是由词法分析器(也称为词法分析器)在词法分析阶段生成的。

那么,令牌究竟长什么样呢?令牌相当简单,通常表示为一个键值对,由令牌名称和某个值(可选)组成。
例如,如果我们对莎士比亚的字符串进行标记化,最终得到的标记主要由字符串字面量和分隔符组成。我们可以将词素“dream”表示为一个标记,如下所示:<字符串字面量, "dream">。类似地,我们可以将词素“.”表示为标记,<分隔符, ".">。
我们会注意到,这些词元并没有对词素进行任何修改——它们只是为词素添加了额外的信息。词元是词素或词汇单位的扩展,包含更多细节;具体来说,这些扩展细节告诉我们,我们正在处理的是哪一类词元(哪种类型的“词”)。
现在我们已经对莎士比亚的句子进行了分词,可以看到源文件中词元类型其实并不丰富。我们的句子只包含字符串和标点符号——但这只是词元的冰山一角!词素还可以被归类到许多其他类型的“词”中。
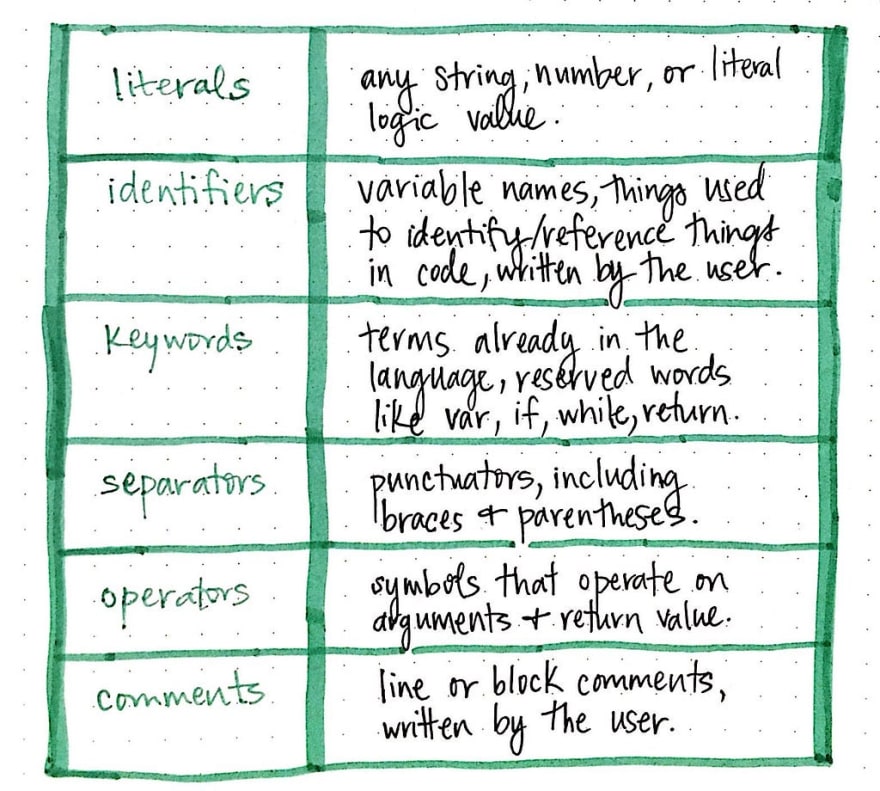
下表展示了编译器在读取几乎所有编程语言的源文件时最常遇到的一些标记。我们看到了字面量(可以是任何字符串、数字或逻辑/布尔值)以及分隔符(任何类型的标点符号,包括花括号 ({}) 和圆括号 (()))的示例。
然而,编程语言中也存在关键字,即语言中保留的术语(例如 if、var、while、return),以及运算符,它们对参数进行操作并返回值(+、-、x、/)。我们还会遇到一些词素,它们可以被标记化为标识符,通常是变量名或用户/程序员用来引用其他内容的语句;此外还有注释,可以是用户编写的行注释或代码块注释。
我们原来的句子只展示了两个词法单元的例子。让我们把句子改写成:var toSleep = "to dream";。编译器会如何对莎士比亚的这个版本进行词法分析呢?

在这里,我们会看到更多种类的标记。关键字 `var` 用于声明变量,标识符 `toSleep` 用于命名变量,或者说引用即将得到的值。接下来是运算符 `=`,后面跟着字符串字面量 `to dream`。语句以分号 `;` 结尾,表示行尾和空格分隔符。
关于词法分析过程,需要注意的一点是,我们既不会对任何空白字符(空格、换行符、制表符、行尾等)进行词法分析,也不会将其传递给解析器。请记住,只有词法单元(token)才会被传递给解析器,并最终出现在解析树中。
值得一提的是,不同语言对空白字符的定义也不同。例如,在某些情况下,Python 编程语言会使用缩进(包括制表符和空格)来指示函数的作用域变化。因此,Python 编译器的词法分析器需要意识到,在某些情况下,制表符或空格实际上需要被作为一个单词进行词法分析,因为它们确实需要传递给解析器!

分词器的这一特性很好地体现了词法分析器/分词器与扫描器的区别。扫描器本身并不了解文本结构,它只知道如何将文本分解成更小的组成部分(即“词”),而词法分析器/分词器则更加智能、更加精确。
分词器需要了解被编译语言的复杂细节和规范。如果制表符很重要,它就需要知道;如果换行符在被编译语言中有特定的含义,分词器也需要了解这些细节。另一方面,扫描器甚至不知道它要分割的单词是什么,更不用说它们的含义了。
编译器的扫描器与语言无关性更强,而分词器根据定义必须是特定于语言的。
词法分析过程的这两个部分相辅相成,是编译过程第一阶段的核心。当然,不同的编译器设计各有特色。有些编译器将扫描和词法分析合并在一个进程中,作为一个单独的程序完成;而另一些编译器则会将它们拆分到不同的类中,在这种情况下,词法分析器在运行时会调用扫描器类。

无论哪种情况,词法分析步骤对于编译都至关重要,因为语法分析阶段直接依赖于它。尽管编译器的每个部分都有其特定的功能,但它们彼此相互依存——就像好朋友之间那样。
资源
由于编译器的编写和设计方法多种多样,因此教授编译器的方法也多种多样。如果你对编译的基础知识进行足够的研究,就会发现有些解释比其他解释详细得多,而这些详细程度可能对你有所帮助,也可能没有帮助。如果你想了解更多,以下是一些关于编译器的资源——重点关注词法分析阶段。
- 第四章——培养译员,罗伯特·尼斯特罗姆
- 编译器构造,艾伦·戈特利布教授
- 编译器基础,詹姆斯·艾伦·法雷尔教授
- 编写编程语言——词法分析器,安迪·巴拉姆
- 解析器和编译器工作原理笔记,斯蒂芬·雷蒙德·弗格
- 词元和词素有什么区别?(StackOverflow)
文章来源:https://dev.to/vaidehijoshi/reading-code-right-with-some-help-from-the-lexer-61d