自然语言处理导论
由 Mux 主办的 DEV 全球展示挑战赛:展示你的项目!
什么是NLP?
不要和神经语言程序学混淆🤦
自然语言处理技术使计算机能够访问以语音或文本形式表达的非结构化数据。语音或文本数据确实包含语言结构。语言结构因语言而异。
——本德,2019
NLP 是一类处理自然语言文本的任务(计算机算法),例如:命名实体识别 (NER)、词性标注 (POS)、文本分类、指代消解等。
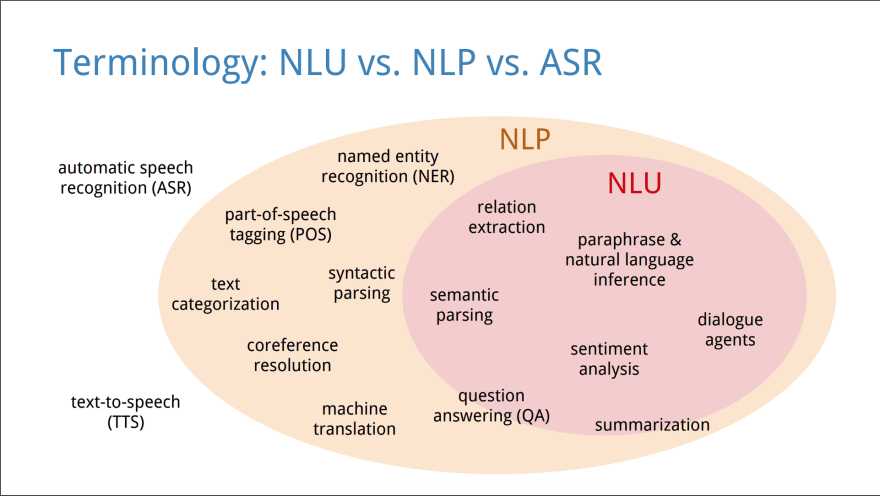
图片来源:理解自然语言理解
有关更详细的任务分类,请参阅paperswithcode和nlpprogress 。
入门
我目前还不是机器学习专家,但我了解一些开发者体验,所以我将展示如何快速轻松地入门自然语言处理。
我们将使用:
- Docker
- Jupyter笔记本
- Python 与spaCy
这个领域有很多工具,但我觉得这些工具比较容易上手,也比较现代。
设置
创造Dockerfile:
FROM jupyter/datascience-notebook:1386e2046833
RUN pip install spacy
RUN python -m spacy download en_core_web_sm
我们将使用强大的Jupyter Docker Stacks。
添加docker-compose.yml:
version: "3"
services:
web:
build: .
ports:
- "8888:8888"
volumes:
- ./work:/home/jovyan/work
跑步
(在终端中,在创建文件的同一文件夹中运行):
docker-compose up
此命令将下载、构建并启动开发环境。您将看到文本。
To access the notebook, copy and paste one of these URLs:
http://127.0.0.1:8888/?token=...

- 在浏览器中打开该网址
- 导航至“工作”文件夹
- 点击右上角的“新建”,从下拉菜单中选择“Python 3”。
你的笔记本电脑已准备就绪,可以开始工作了。

Jupyter notebook 是实验运行时环境和科学期刊的结合体。
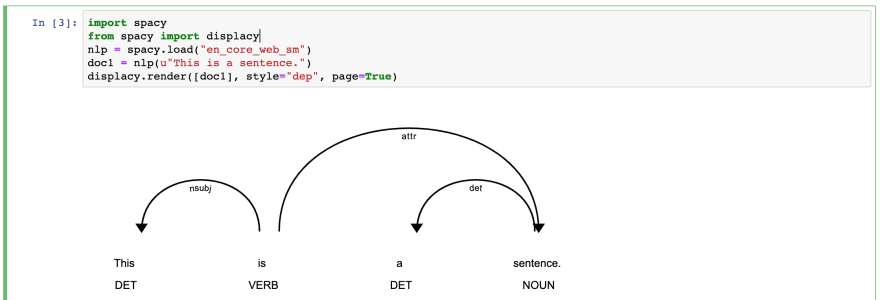
第一个实验:POS
POS 代表词性标注——我们需要识别给定文本中每个单词的词性,例如名词、动词。
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc1 = nlp(u"This is a sentence.")
displacy.render([doc1], style="dep", page=True)
输入程序名称,然后点击“运行”。
第二个实验:命名实体识别(NER)。
NER 代表命名实体识别。这项任务旨在区分特定的实体,例如由多个部分组成的人名(悉达多·乔达摩)、国家名称(英国)或金额(10亿美元)。
import spacy
from spacy import displacy
text = u"When Sebastian Thrun started working on self-driving cars at Google in 2007, few people outside of the company took him seriously."
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
displacy.render(doc, style="ent")
输入程序名称,然后点击“运行”。

保存您的工作
将笔记本(点击“未命名”)重命名为更有意义的名称,例如“实验”。点击“保存”按钮。
创建.gitignore文件:
work/.ipynb_checkpoints
(在终端中,在创建文件的同一文件夹中运行):
git init
git add .
git commit -m "first commit"
现在你已经将工作保存到 Git 中了。
教程
这些实验的目的是为了展示入门有多容易。如果你想真正学习它,可以参考这篇教程。
祝你好运!
PS
访问spaCy universe查看更多精彩项目。spaCy 只是众多工具之一,您也可以使用任何其他您喜欢的工具,例如 nltk、Stanford CoreNLP 等。
文章来源:https://dev.to/stereobooster/introduction-to-natural-language-processing-38ei照片由 Green Chameleon 拍摄,来自 Unsplash