使用 Nebius,几分钟内即可优化您的 LLM 课程 ⚡️
介绍
大型语言模型很棒!但在执行特定任务或成为领域专家方面,它就没那么好了。
这就需要进行微调了!
在本文中,我将分享如何使用 Nebius Ai Studio 在几分钟内微调您的 LLM。
那么,事不宜迟,
开始吧!
什么是微调?

在开始之前,让我们先了解一下什么是微调!
简单来说,微调是指将预训练模型在特定领域的数据集上进行进一步训练的过程。
我们都知道如今的LLM(学习生命周期模型)功能强大,但它们在处理特定任务方面远非完美。而使其成为专家的最佳方法之一,就是利用领域特定知识进行微调。
这意味着针对我们想要完成的具体任务,对模型的某些部分进行重新训练。这比重新训练整个模型成本更低。
然而,对于像我这样并非传统机器学习工程师的人来说,微调 LLM 并非易事。Nebius AI Studio 让微调开源 LLM 变得更加容易。
凭借其直观的用户界面平台或 Python SDK,无论是否精通编程,每个人都可以轻松进行微调。
🎥想快速学习一下吗?观看这个分步视频:
如何利用Nebius微调您的LLM
现在,让我们看看如何使用 Nebius AI Studio 轻松微调 LLM。
因此,Nebius AI Studio提供了三种方法来微调您的 LLM:
-
Web 控制台– 无需编写代码即可轻松进行微调。
-
Python SDK – 一种使用 Python 的对开发者友好的方法。
-
cURL 请求– 基于 API 的自动化和脚本微调。
我们将看看如何使用每种方法来微调你的模型。
先决条件
1. 选择型号
首先,您需要选择要微调的模型。Nebius AI Studio 支持对30 多种主流模型进行微调,其中包括:
-
Llama 3 系列(1B–70B 参数)
-
Qwen系列(1.5B–72B参数)
-
DeepSeek R1和其他专用型号
您可以浏览可用型号,并选择适合您使用情况的型号。
2. 准备数据集
接下来,您需要准备用于训练模型和验证训练结果的数据集。Nebius AI Studio 支持JSON Lines 格式. jsonl的数据集文件。
💡 提示:将数据分成两个数据集,训练集占 80-90%,验证集占 10-20%。
3. 获取您的 API 密钥
获取 Nebius API 密钥并将其存储在.env变量中。
NEBIUS_API_KEY=<Your_API_key>
完成这些步骤后,就可以开始微调模型了。
通过 Web 控制台进行微调(无需编码)

微调LLM的最简单方法是通过Nebius AI Studio的Web控制台。您无需为此编写任何代码。
-
登录Nebius AI Studio并进入微调部分。
-
上传您的训练数据集和验证数据集。
-
选择您的模型和微调参数。
-
点击“创建职位”。
-
使用所需模型名称下的“检查点”链接下载包含微调模型的文件。
我制作了一个视频来演示如何操作,你可以在这里查看。
通过 Python SDK 进行微调
如果您更喜欢使用 Python,可以使用 Nebius 的 Python SDK 以编程方式微调您的模型。
1. 安装依赖项
首先,我们将使用以下命令安装依赖项:
pip3 install openai
2. 设置 OpenAI 客户端
使用 Nebius AI 的 API 端点和您的 API 密钥设置 OpenAI 客户端
import os
from openai import OpenAI
import time
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY"),
)
3. 上传您的数据集
接下来,我们将上传之前创建的训练数据集和验证数据集。
# Upload a training dataset
training_dataset = client.files.create(
file=open("<dataset_name>.jsonl", "rb"), # Specify the dataset name
purpose="fine-tune"
)
# Upload a validation dataset
validation_dataset = client.files.create(
file=open("<dataset_name>.jsonl", "rb"), # Specify the dataset name
purpose="fine-tune"
)
4. 创建微调作业
之后,我们需要定义微调参数,例如训练轮数以及是否使用LoRA 自适应以提高效率。
如果要添加更多参数,请查看Nebius 文档以获取更多信息。
job_request = {
"model": "meta-llama/Llama-3.1-8B-Instruct", # Choose the model
"training_file": training_dataset.id,
"validation_file": validation_dataset.id,
"hyperparameters": {
"n_epochs": 3, # Number of epochs for training
"lora": True, # Enable LoRA for fine-tuning efficiency
},
"integrations": [],
}
然后我们将创建并运行微调作业
# Create and run the fine-tuning job
job = client.fine_tuning.jobs.create(**job_request)
5. 监控作业状态
如果您正在对模型进行微调,这meta-llama/Llama-3.1-70B-Instruct可能需要一些时间。为此,我们会定期检查任务是否仍在运行或已完成:
# Make sure that the job has been finished or cancelled
active_statuses = ["validating_files", "queued", "running"]
while job.status in active_statuses:
time.sleep(15)
job = client.fine_tuning.jobs.retrieve(job.id)
print("current status is", job.status)
print("Job ID:", job.id)
6. 获取检查点并保存
微调过程会创建多个检查点(模型的中间版本)。我们将检索这些检查点并将文件保存到这些目录中。
if job.status == "succeeded":
# Check the job events
events = client.fine_tuning.jobs.list_events(job.id)
print(events)
for checkpoint in client.fine_tuning.jobs.checkpoints.list(job.id).data:
print("Checkpoint ID:", checkpoint.id)
# Create a directory for every checkpoint
os.makedirs(checkpoint.id, exist_ok=True)
for model_file_id in checkpoint.result_files:
# Get the name of a model file
filename = client.files.retrieve(model_file_id).filename
# Retrieve the contents of the file
file_content = client.files.content(model_file_id)
# Save the contents into a local file
file_content.write_to_file(filename)
我们已经对模型进行了微调!接下来,我们将展示这些模型。
您可以在 Google Colab 上以交互方式尝试此方法: Colab Notebook
通过 cURL 请求进行微调
如果您更喜欢基于 API 的微调或想要自动化该过程,您可以使用cURL 请求直接与 Nebius AI Studio 进行交互。
1. 上传您的数据集
运行以下 cURL 命令上传您的训练数据集:
curl 'https://api.studio.nebius.com/v1/files' \
-H 'Accept: application/json' \
-H 'Content-Type: multipart/form-data' \
-H "Authorization: Bearer $NEBIUS_API_KEY"
-F 'file=@<dataset-name>.jsonl' \
-F 'purpose=fine-tune'
💡 注意:保存响应中的文件 ID;创建微调作业需要用到它。
同样,请上传您的验证数据集:
curl 'https://api.studio.nebius.com/v1/files' \
-X 'POST' \
-H 'Authorization: Bearer $NEBIUS_API_KEY' \
-H 'Accept: application/json' \
-H 'Content-Type: multipart/form-data' \
-F 'file=@validation_dataset.jsonl' \
-F 'purpose=fine-tune'
2. 发送微调请求:
现在,我们将运行以下命令来创建一个微调作业:
curl 'https://api.studio.nebius.com/v1/fine_tuning/jobs' \
-X 'POST' \
-H 'Authorization: Bearer $NEBIUS_API_KEY' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta-llama/Llama-3.1-8B-Instruct",
"training_file": "your_training_file_id",
"validation_file": "your_validation_file_id",
"hyperparameters": {
"n_epochs": 3,
"batch_size": 8,
"learning_rate": 0.0001,
"lora": true,
"lora_r": 16,
"lora_alpha": 32,
"lora_dropout": 0.1,
"weight_decay": 0.01
}
}'
💡 请替换占位符:
"your_training_file_id"→ 第二步中的文件 ID。
"your_validation_file_id"→ 第二步中的文件 ID。
提交后,Nebius AI Studio 会返回一个作业 ID。请妥善保管此 ID 以便跟踪进度。
4. 监控微调作业
微调需要时间。要检查作业状态,请运行以下命令:
curl 'https://api.studio.nebius.com/v1/fine_tuning/jobs/<job_ID>' \
-X 'GET' \
-H 'Accept: application/json' \
-H 'Authorization: Bearer $NEBIUS_API_KEY'
请确保培训已成功完成。为此,请检查作业事件。作业事件会在作业状态发生变化时创建。
curl 'https://api.studio.nebius.com/v1/fine_tuning/jobs/<job_ID>/events' \
-X 'GET' \
-H 'Accept: application/json' \
-H 'Authorization: Bearer $NEBIUS_API_KEY' \
--url-query limit=<...> \
--url-query after=<...>
5. 获取检查点
微调完成后,您可以检索已训练模型的检查点。这些是模型在不同阶段保存的中间版本。
curl 'https://api.studio.nebius.com/v1/fine_tuning/jobs/<job_ID>/checkpoints' \
-X 'GET' \
-H 'Accept: application/json' \
-H 'Authorization: Bearer $NEBIUS_API_KEY'
我们将从响应中获取检查点 ID。
每个检查点都包含多个文件,这些文件分别包含微调模型的不同部分。要获取文件名和扩展名,请使用:
curl 'https://api.studio.nebius.com/v1/files/<file_ID>' \
-X 'GET' \
-H 'Accept: application/json' \
-H 'Authorization: Bearer $NEBIUS_API_KEY'
对检查点中的每个文件重复此请求,以下载所有必需的文件。
6. 下载微调模型
获取模型文件内容后,请务必使用正确的文件名和扩展名保存它们。
curl 'https://api.studio.nebius.com/v1/files/<file_ID>/content' \
-X 'GET' \
-H 'Accept: application/json' \
-H 'Authorization: Bearer $NEBIUS_API_KEY'
对检查点中的每个文件重复此请求,以下载所有必需的文件。
7. 正确保存模型文件
获取模型文件内容后,请务必使用正确的文件名和扩展名保存它们。
在 Nebius AI Studio 上托管您精心调校的模型
模型微调完成后,下一步就是让它方便自己和他人使用。将模型托管在Nebius AI Studio上,即可轻松部署和使用。
无论是经过精细调整的LLM还是LoRA适配器,您都可以通过该平台直接申请托管。
开始之前,请确保您已具备:
✅ 一个已优化好并可供部署的模型。✅
一个包含模型文件的共享云存储链接(已打包)。
按照以下简单步骤即可在 Nebius AI Studio 中托管您的模型:
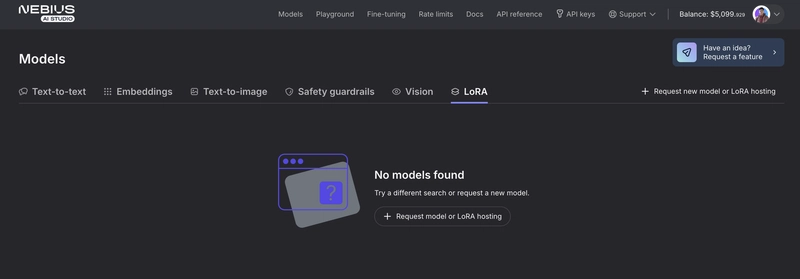
在Web 控制台中,转到“微调”部分。
-
点击 请求模型或 LoRA 托管
-
在打开的窗口中,选择“请求 LoRA 模型托管”。
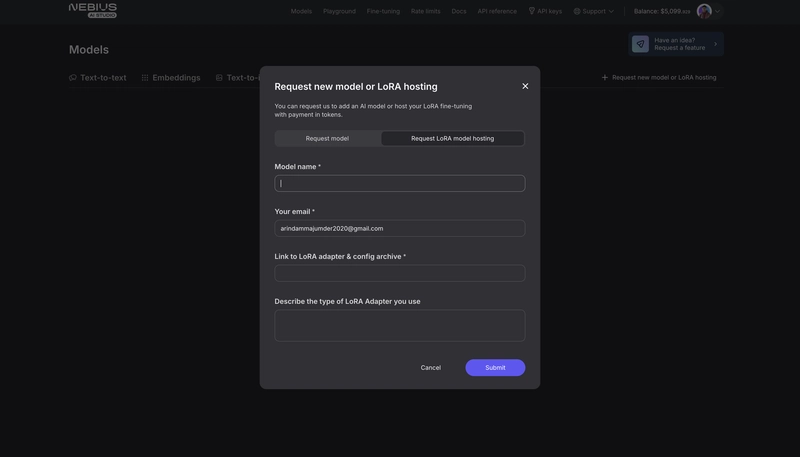
-
请输入型号名称并确保您的电子邮件地址正确。
-
粘贴您的模型文件存档链接,并(如果适用)描述您的LoRA 适配器类型。
-
点击“提交”,您的请求将发送给Nebius AI 支持团队进行处理。


审核通过后,您的模型将被托管并可供使用!
结论
总结完毕!在本文中,我们学习了如何通过 3 种不同的方法轻松地对我们的 LLM 进行微调。
如果您觉得这篇文章有用,请与您的朋友和社区分享,让更多人了解这篇文章。
欢迎留言,如有任何疑问,请私信我!

付费合作请联系:arindammajumder2020@gmail.com。
感谢阅读!
