🎓🧠 掌握、表达与精进:你的实时语音教练,助你更高效地记忆和掌握学术知识 🎤📚⚡
🧠✨📈 掌握、表达、提炼
这是参加AssemblyAI 语音代理挑战赛的作品。
💡我打造的
一款实时、人工智能驱动的学术听力辅导工具,旨在帮助您:
- 掌握任何概念
- 请用你自己的话表达出来
- 从经过训练、能像特定领域教育者一样做出回应的人工智能导师那里获得实时反馈。
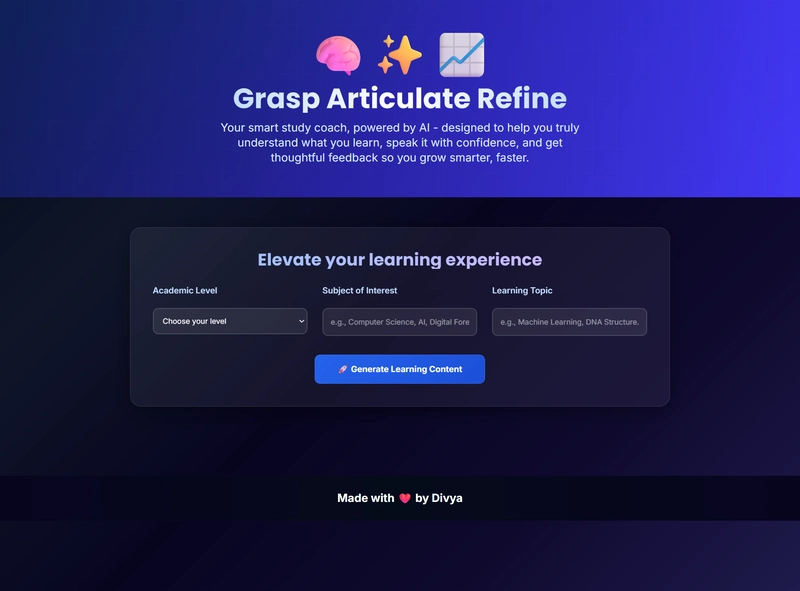
想象一下,一个专为学术界人士打造的个性化聆听型演讲俱乐部,它:
✅ 边听边说
✅ 实时转录
✅ 分析你的回答
✅ 提供建设性反馈
✅ 评分标准是你的清晰度、语气和结构,而不是你本人😅
非常适合口试准备、论文答辩、求职面试,更好地掌握概念或主题,甚至可以大声解释复杂的概念。
✨我为什么建造它
我一直渴望找到一位真正能适应我的导师——
一位倾听而不加评判的导师;
一位在意我说话方式而不仅仅是我说什么的
导师; 一位在我停顿时耐心等待的导师;一位在我语塞时帮助我找到表达方式的导师。
作为一名需要在实习、考试、黑客马拉松和生活之间周旋的学生,我经常发现自己:
- 压力下喃喃自语
- 回答过程中语无伦次
- 或者在面试中完全大脑一片空白。
所以,我为过去的自己打造了这个平台。
那个紧张的学生。那个沉默寡言的开发者。
那个明明知道答案,却无法清晰表达的人。
这不仅仅是一个工具,
它还是你笔记本电脑里一个温柔又有点书呆子气的好朋友,时刻提醒你:
“你能行的。说出来,我会帮你完善它。”
哦,如果你过度使用语气词?
它会温柔地💘嘲讽你:
“闺蜜,你刚才说了27次‘嗯’,咱们来纠正一下。”
🛠️功能
1️⃣ 🎙️开启麦克风,开启大脑!
直接通过浏览器进行实时语音输入(无需安装应用程序!)
2️⃣ ✍️实时耳语:
通过 ⚡ AssemblyAI 的 Streaming API 实现即时语音转文本
3️⃣ 📊即时成绩单
根据关键沟通指标获得 10 分制评分:
- 🗣️流利度
- 🧩相干性
- 🔁冗余
- 🧠技术深度
- 💪自信指标
📈 实时呈现 → 您的成长,可视化呈现。
4️⃣ 🎓 AI 教育者模式
你的演讲将像你向领域专家讲解一样得到评估(Groq)
5️⃣ 🔁反复尝试直到成功 出错
?再说一遍。每次都更聪明。🔁
6️⃣ 🎯专注的单人练习
一个安静的道场,训练你的心口协调能力 🤐🧘♀️
7️⃣ 🧪专为认真学习者打造,
非常适合:
- 🧬 口试/论文准备
- 🧑💻 技术面试
- 📚 学术演讲
- 🎤 流利度练习
- ✨ 更好地掌握任何主题
8️⃣ 💻极简界面,极致效果
。摒除一切干扰,只专注于你、你的想法和你的成长💥
🎬演示
这是我的实时项目:- Grasp Articulate Refine
⚠️ Chrome浏览器效果最佳。Firefox浏览器表现不佳。Brave浏览器表现出色。Safari浏览器则……比较害羞。
你可以在这里查看我的项目展示:
GitHub 仓库
👉👇
🧠✨📈 掌握、表达、提炼
您的智能学习教练,由人工智能驱动——旨在帮助您真正理解所学内容,自信地表达,并获得深思熟虑的反馈,从而让您更快、更聪明地成长。
我的项目概览:

点击此处观看直播:-掌握、表达、精炼
✨ 特点
- 自适应内容生成:根据您的学术水平创建 2000-3000 字的教育内容
- 基于语音的评估:使用 Assembly AI 进行语音转文本转录
- 人工智能驱动的分析:扮演全球知名教育家的角色,提供详细的反馈
- 智能评分:对答案进行评分,满分10分,并提供详细解释。
- 进度跟踪:学生必须获得9分及以上才能进入下一主题的学习。
- 庆祝系统:表现优异者可获得 3 秒表情符号叠加效果(🥳🎉🎊)
- 移动响应式:深蓝色主题,高对比度设计
- 真实参考资料:提供与解释相关的有效参考链接
- 涵盖多个学术级别:高中、本科、研究生、专业
- 自定义主题…
如果你更擅长编写代码,或者想分析我的代码🤔,从中汲取灵感,可以查看我上面的代码库,进行 fork、克隆,然后在本地设备上进行开发。
技术实施与 AssemblyAI 集成
以下是展示本项目技术实现和 AssemblyAI 集成的代码片段:
🎯 1. AssemblyAI 初始化和配置
python
# utils/voice_manager.py - AssemblyAI Setup
import assemblyai as aai
class VoiceManager:
def __init__(self, api_keys: Dict[str, str]):
self.api_keys = api_keys
self.assemblyai_available = False
self._init_assemblyai()
def _init_assemblyai(self):
if ASSEMBLYAI_AVAILABLE and self.api_keys.get('ASSEMBLYAI_API_KEY'):
try:
aai.settings.api_key = self.api_keys['ASSEMBLYAI_API_KEY']
test_config = aai.TranscriptionConfig(
language_detection=True,
punctuate=True,
format_text=True,
speaker_labels=False,
auto_highlights=False
)
self.assemblyai_available = True
print("✅ AssemblyAI initialized successfully")
except Exception as e:
print(f"❌ AssemblyAI initialization failed: {e}")
self.assemblyai_available = False
使用 API 密钥设置 AssemblyAI SDK,并配置转录设置,包括语言检测、标点符号和文本
格式。初始化 VoiceManager 类,该类具有针对教育内容转录优化的增强功能。
🎤 2. 核心音频转录实现
python
def transcribe_audio(self, audio_file_path: str) -> str:
if not os.path.exists(audio_file_path):
return "❌ Audio file not found"
# Primary Method: AssemblyAI SDK
if self.assemblyai_available:
try:
print("🔄 Trying AssemblyAI SDK...")
config = aai.TranscriptionConfig(
language_detection=True,
punctuate=True,
format_text=True,
speaker_labels=False,
auto_highlights=False )
transcriber = aai.Transcriber(config=config)
transcript = transcriber.transcribe(audio_file_path)
if transcript.status == "completed":
print("✅ AssemblyAI SDK transcription successful")
return self._clean_transcription(transcript.text)
elif transcript.status == "error":
print(f"❌ AssemblyAI SDK error: {transcript.error}")
return f"❌ Transcription error: {transcript.error}"
except Exception as e:
print(f"❌ AssemblyAI SDK error: {e}")
# Fallback Method: Direct API
if self.api_keys.get('ASSEMBLYAI_API_KEY'):
try:
print("🔄 Trying AssemblyAI Direct API...")
result = self._transcribe_with_api(audio_file_path)
if result and not result.startswith("❌"):
print("✅ AssemblyAI API transcription successful")
return self._clean_transcription(result)
except Exception as e:
print(f"❌ AssemblyAI API error: {e}")
return "❌ Transcription failed. Please check API configuration."
主要转录功能采用双模式方法:主要使用 AssemblyAI SDK 方法,并可回退到直接 API。它能够处理音频文件
验证、通过增强的配置进行转录,并包含全面的错误处理机制,从而实现可靠的语音转
文本转换。
🔧 3. 直接 API 实现及增强功能
python
# utils/voice_manager.py - Direct API Implementation
def _transcribe_with_api(self, audio_file_path: str) -> str:
"""
Direct AssemblyAI API implementation with robust error handling
"""
try:
headers = {'authorization': self.api_keys['ASSEMBLYAI_API_KEY']}
print("📤 Uploading audio file...")
with open(audio_file_path, 'rb') as f:
response = requests.post(
'https://api.assemblyai.com/v2/upload',
headers=headers,
files={'file': f},
timeout=60
)
if response.status_code != 200:
return f"❌ Upload failed: {response.status_code} - {response.text}"
upload_url = response.json()['upload_url']
print(f"✅ File uploaded: {upload_url}")
print("🔄 Requesting transcription...")
data = {
'audio_url': upload_url,
'language_detection': True,
'punctuate': True,
'format_text': True,
'speaker_labels': False,
'auto_highlights': False
}
response = requests.post(
'https://api.assemblyai.com/v2/transcript',
headers=headers,
json=data,
timeout=30
)
if response.status_code != 200:
return f"❌ Transcription request failed: {response.status_code}"
transcript_id = response.json()['id']
print(f"🔄 Transcription ID: {transcript_id}")
print("⏳ Waiting for transcription to complete...")
max_attempts = 60 # 2-minute timeout
attempt = 0
while attempt < max_attempts:
response = requests.get(
f'https://api.assemblyai.com/v2/transcript/{transcript_id}',
headers=headers,
timeout=30
)
if response.status_code != 200:
return f"❌ Status check failed: {response.status_code}"
result = response.json()
status = result['status']
if status == 'completed':
print("✅ Transcription completed")
return result['text'] or "❌ No text in transcription result"
elif status == 'error':
error_msg = result.get('error', 'Unknown error')
return f"❌ Transcription error: {error_msg}"
elif status in ['queued', 'processing']:
print(f"⏳ Status: {status} (attempt {attempt + 1}/{max_attempts})")
import time
time.sleep(2) # 2-second polling interval
attempt += 1
else:
return f"❌ Unknown status: {status}"
return "❌ Transcription timeout - took too long to process"
except requests.exceptions.Timeout:
return "❌ Request timeout - please try again"
except Exception as e:
return f"❌ Unexpected error: {str(e)}"
实现直接调用 AssemblyAI API 作为备用方法。支持文件上传、转录请求(具备增强功能)以及
2 分钟超时的智能轮询。提供强大的错误处理机制,以应对网络问题和 API 故障。
🧹 4. 高级文本处理与清理
python
# utils/voice_manager.py - Text Processing
def _clean_transcription(self, text: str) -> str:
if not text:
return "❌ Empty transcription result"
text = text.strip()
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'([.!?])\s*([a-z])',
lambda m: m.group(1) + ' ' + m.group(2).upper(), text)
if text and not text[0].isupper():
text = text[0].upper() + text[1:]
if text and text[-1] not in '.!?':
text += '.'
return text
def validate_audio_file(self, file_path: str) -> Dict[str, any]:
if not os.path.exists(file_path):
return {
'valid': False,
'error': 'File does not exist',
'file_size': 0
}
file_size = os.path.getsize(file_path)
max_size = 100 * 1024 * 1024 # 100MB limit
if file_size > max_size:
return {
'valid': False,
'error': f'File too large: {file_size / (1024*1024):.1f}MB (max 100MB)',
'file_size': file_size
}
if file_size < 1000: # Minimum 1KB
return {
'valid': False,
'error': 'File too small - may be empty or corrupted',
'file_size': file_size
}
return {
'valid': True,
'error': None,
'file_size': file_size,
'file_size_mb': file_size / (1024 * 1024)
}
对转录结果进行后处理,包括文本清理、空格规范化、句子大小写修正和
标点符号校正。此外,还包括音频文件验证,检查文件大小限制和完整性,以确保最佳转录质量。
🌐 5. Flask 集成和 API 端点
python
# app.py - Flask Integration
@app.route('/transcribe_audio', methods=['POST'])
def transcribe_audio():
try:
audio_file = request.files.get('audio')
if not audio_file:
return jsonify({'error': 'No audio file provided'}), 400
session_id = session.get('session_id', 'unknown')
temp_path = f"temp/audio_{session_id}.wav"
os.makedirs('temp', exist_ok=True)
audio_file.save(temp_path)
print(f"🔄 Starting transcription of {temp_path}")
validation = voice_manager.validate_audio_file(temp_path)
if not validation['valid']:
if os.path.exists(temp_path):
os.remove(temp_path)
return jsonify({'error': validation['error']}), 400
transcription = voice_manager.transcribe_audio(temp_path)
if os.path.exists(temp_path):
os.remove(temp_path)
print(f"✅ Transcription result: {transcription[:100]}...")
return jsonify({
'success': True,
'transcription': transcription,
'file_size_mb': validation.get('file_size_mb', 0)
})
except Exception as e:
print(f"❌ Transcription error: {e}")
return jsonify({'error': f'Transcription failed: {str(e)}'}), 500
@app.route('/voice_status')
def voice_status():
return jsonify(voice_manager.get_voice_status())
用于音频转录的 Flask 端点,支持基于会话的临时文件处理。包含全面的错误处理、文件
验证和清理机制。提供语音状态端点,用于实时监控功能可用性并进行诊断。
📊 6. 状态监控与诊断
python
# utils/voice_manager.py - Status Monitoring
def get_voice_status(self) -> Dict[str, bool]:
return {
'assemblyai_available': self.assemblyai_available,
'voice_recording_available': self.assemblyai_available,
'transcription_available': self.assemblyai_available,
'api_key_configured': bool(self.api_keys.get('ASSEMBLYAI_API_KEY')),
'sdk_available': ASSEMBLYAI_AVAILABLE,
'direct_api_available': bool(self.api_keys.get('ASSEMBLYAI_API_KEY'))
}
def _print_status(self):
print("\n🎤 VOICE FEATURES STATUS:")
print(f" AssemblyAI Available: {'✅' if self.assemblyai_available else '❌'}")
print(f" Voice Recording: {'✅' if self.assemblyai_available else '❌'}")
print(f" Audio Transcription: {'✅' if self.assemblyai_available else '❌'}")
print(f" API Key Configured: {'✅' if self.api_keys.get('ASSEMBLYAI_API_KEY') else '❌'}")
print()
用于监控 AssemblyAI 各项功能可用性的综合系统,包括 SDK 状态、API 密钥配置和转录
功能。提供详细的状态报告,便于故障排除和系统健康监控。
🔒 7. 麦克风访问的 HTTPS 配置
python
def create_self_signed_cert():
try:
from cryptography import x509
from cryptography.x509.oid import NameOID
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.primitives.asymmetric import rsa
from cryptography.hazmat.primitives import serialization
import datetime
import ipaddress
private_key = rsa.generate_private_key(
public_exponent=65537,
key_size=2048,
)
subject = issuer = x509.Name([
x509.NameAttribute(NameOID.COUNTRY_NAME, "US"),
x509.NameAttribute(NameOID.STATE_OR_PROVINCE_NAME, "Local"),
x509.NameAttribute(NameOID.LOCALITY_NAME, "Local"),
x509.NameAttribute(NameOID.ORGANIZATION_NAME, "AI Learning Platform"),
x509.NameAttribute(NameOID.COMMON_NAME, "localhost"),
])
cert = x509.CertificateBuilder().subject_name(
subject
).issuer_name(
issuer
).public_key(
private_key.public_key()
).serial_number(
x509.random_serial_number()
).not_valid_before(
datetime.datetime.utcnow()
).not_valid_after(
datetime.datetime.utcnow() + datetime.timedelta(days=365)
).add_extension(
x509.SubjectAlternativeName([
x509.DNSName("localhost"),
x509.DNSName("127.0.0.1"),
x509.IPAddress(ipaddress.IPv4Address("127.0.0.1")),
]),
).sign(private_key, hashes.SHA256()) certificate and key
with open("cert.pem", "wb") as f:
f.write(cert.public_bytes(serialization.Encoding.PEM))
with open("key.pem", "wb") as f:.private_bytes(
encoding=serialization.Encoding.PEM,
format=serialization.PrivateFormat.PKCS8,
encryption_algorithm=serialization.NoEncryption()
))
print("✅ Self-signed certificate created")
return True
except Exception as e:
print(f"❌ Failed to create certificate: {e}")
return False
创建浏览器麦克风访问所需的自签名 SSL 证书。为本地主机生成加密证书,并进行
正确的域名配置,从而在教育平台的 Web 浏览器中启用安全音频录制功能。
技术栈使用情况
后端
- Python + Flask - 用于处理会话和推理
- AssemblyAI - 实时转录(流媒体 API)
- Groq (LLaMA3-8B) - 用于即时反馈
前端
- JavaScript - 音频流 + Web Audio API
- HTML/CSS - 简洁、响应式、注重清晰度
💭 结语
这不仅仅是一份作业,
这是一封写给每一个害羞、书呆子气的学生的情书💌💌,他们曾经渴望自己的想法能够更清晰地表达出来。
这真有意思。
我们花了多年时间学习各种知识,却从来没有人费心教我们如何把它们表达清楚。
这个项目就是我弥补这一缺憾的方式——用代码、用心和麦克风。
我会在此基础上继续创作吗?当然会。
如果我赢了我会哭吗?可能会。
如果我输了我会继续改进吗?毫无疑问。🥹
🫶 感谢聆听(字面意义上的)
致各位评委、导师以及每一位阅读此文的开发者——
让我们更好地表达,让我们更响亮地建设,
或许……还能在这个过程中少一些结巴。
🎤💙
迪维娅·辛格
感谢您阅读到最后。

文章来源:https://dev.to/divyasinghdev/grasp-enchant-refine-your-real-time-voice-coach-for-smarter-recall-academic-mastery-p95


