错误日志记录模式和实践
本文是我之前发表的《给开发新手的 5 个技巧》一文的延伸。原文章的目的是详细阐述一些重要的概念,帮助你在工作中不断改进。
我想更详细地探讨一下日志记录的问题,所以我决定单独写一篇文章。
我需要关注日志吗?
如果日志记录不完整,查找漏洞时就像在黑暗中摸索。更糟糕的是,如果根本没有日志记录机制,你甚至都不知道存在漏洞。
有了日志,你早上起来就能一边喝咖啡一边查看昨晚几个小时发生的错误。如果是已知问题,你可能不会觉得它有多重要**。但是,如果出现新的、意料之外的问题,一份格式清晰、包含明确错误信息的堆栈跟踪信息绝对会让你恍然大悟:“我抓到你了,你这小混蛋!”
通过日志,您可以轻松找到客户帐户上发生的情况,而无需进行更长时间的访谈。
如何判断应用程序的日志记录功能是否出现问题?嗯,它可能会以多种不同的方式出现故障。
我不会深入探讨哪个日志库或日志处理管道最好(毕竟,处理管道对初级开发人员来说并非太容易理解的内容)。我更想讨论一些更基础、更宏观的概念。
这意味着要么应该修复这些问题,要么你应该记录一些可能应该省略的内容?
理解你的框架
大多数现代框架(至少后端框架)都内置了日志记录功能。虽然日志信息和警告消息的含义显而易见,但错误处理却可能涉及多种场景,许多开发者往往忽略了这些知识,抱着“随便用个方法记录日志就行了”的想法。然而,事实并非如此。更糟糕的是,如果使用不当,日志记录会变成无用的信息。
有些库使用类似 error(message) 的方法记录错误,并在日志中生成包含该消息、时间戳和日志级别的条目。
有些方法有单独的方法来记录异常对象,例如logException(Exception e)
它通常会接收异常消息并将其与堆栈跟踪结合起来,然后将其作为错误条目添加到日志中。
另一种常见的做法是使用类似 error 的方法,但允许添加上下文或异常对象——然后该方法提取堆栈跟踪并在此基础上构建适当的错误消息。
花 2 分钟时间阅读框架或日志库的 #logging 部分的文档。
代码级错误
在使用我们应用程序的日志机制时,存在许多基本的代码级错误。最常见的是处理异常时出现的错误。
举例来说,假设我们的应用程序是一个网络爬虫,用于从某个招聘网站提取数据。我们想要获取目标招聘网站首页上每个职位的详细信息。我们使用 abstract 请求页面HttpClient。
在开始之前,我们先来做一个小小的思维实验。对于每种情况——想象一下,假设你编写的代码中出现了错误,你的同事第二天早上到办公室后会在日志中看到什么。
完全不记录异常。我在代码库中见过太多次这种情况了。try { httpClient.get(url) } catch (e) { }

假设你的应用程序抓取程序应该抓取 2000 个 URL,但在 yetanotherjobboard.io/junior-web-dev 上失败了。
星期一早上。你的同事正在享用他的第一杯咖啡——同时查看日志,了解夜间发生了什么。他会在日志中看到什么?
一片空白。
你甚至不知道,夜间有些网址没有被解析。
在这种情况下,修复日志记录问题显而易见。假设你的logException方法能够正确处理日志记录异常,并且没有犯以下任何错误,那么它应该像这样:
try { httpClient.get(url) } catch (e) { logger.logException(e); }
本示例假设该logException方法会保存所有重要信息。否则,我们需要单独保存异常及其相关信息。请参阅以下示例。
- 仅记录日志,不添加出错原因的详细信息。
Try {
httpClient.get(url)
} catch (e) {
logger.logException(e);
logger.logError(‘Was not able to parse URL’);
}
这比问题 1) 要好,因为至少我们知道发生了意外情况,但仍然缺少问题的关键部分。这也是我在“理解你的框架”部分提到的一个例子。我们有两个不同的方法——一个用于记录异常本身,另一个用于保存包含我们自定义错误消息的条目。
如果解析器未能处理某个 URL,你的队友会在第二天早上看到什么?
HttpClient 出错的堆栈跟踪信息及出错代码行。
此外,下一条日志信息将是“无法解析 URL”。
不错,但如果你想修复解析器,就需要知道哪个 URL 没有被解析。你可以把这个 URL 输入浏览器,或者在命令行中使用 curl 命令手动检查失败原因。
修复此问题后,代码将变为这样:
Try {
httpClient.get(url)
} catch (e) {
logger.logException(e);
logger.logError(‘Was not able to parse url ’ + url);
}
- 仅将异常记录为错误消息,不记录堆栈跟踪信息。堆栈跟踪信息的重要性不亚于甚至超过提供有意义的错误消息。
Try {
httpClient.get(url)
} catch (e) {
logger.logError(‘Was not able to parse url ’ + url);
}
这个例子主要取决于logError消息的实现方式,但我假设它只记录传递的消息,并将条目标记为错误。
在这种情况下,你想知道:
哪个 URL 解析失败 - 已检查;
失败原因 - 未检查。可能是因为解析的网站暂时出现故障,导致我们收到 500 响应。也可能是我们的 HTTP 客户端由于网络问题而超时。或者我们的解析器可能被禁用了?
修复方法取决于您代码中的其他部分和类,但可能与此类似。堆栈跟踪(记录异常本身)将有助于解答我们的问题。
Try {
httpClient.get(url)
} catch (e) {
logger.logError(‘Was not able to parse url ’ + url);
logger.logException(e);
}
成为命令行日志忍者
最后,我想提一下处理日志的方法。学习如何以便捷的方式查看日志非常重要。如果您是 Windows 用户,需要直接在 Linux 机器上查看日志,这一点尤为重要。
如果您是那种习惯先寻找应用程序图形界面对应界面的用户,而现在却需要直接在命令行或数据库控制台中查看日志,您可能会感到有些不知所措。请尝试以下在 Linux 终端中读取日志的命令:
tail -f -n 200 /var/logs/nginx.log
并养成习惯。
添加-F用于连续显示新行的参数也很有帮助。

如果您需要在 MySQL 控制台中处理日志,您可能会发现以下 SQL 开关很有用\G——它可以更好地显示多行列,并生成以下格式的日志:
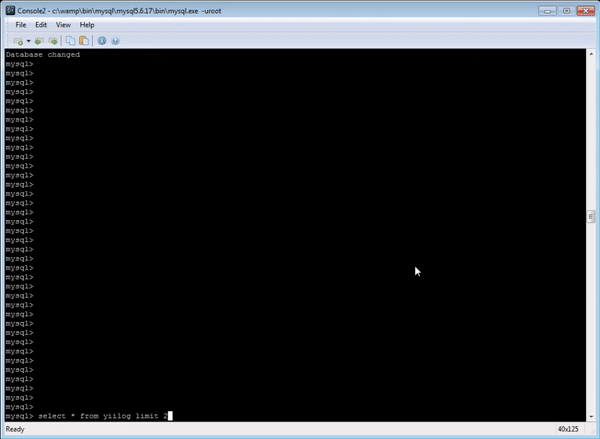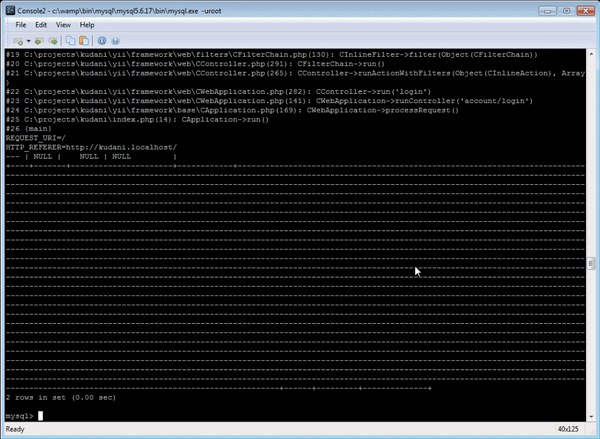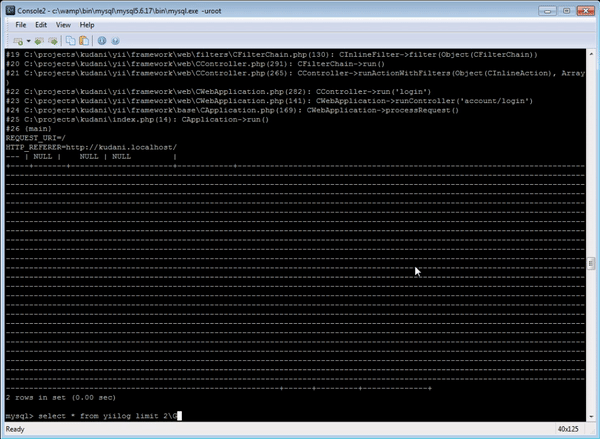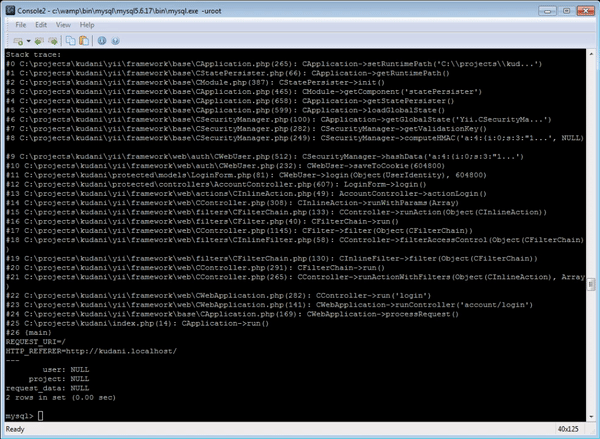
学习如何快速将机器可读的时间戳转换为可读格式(例如 SQL 语句)from_unixtime(col)是一个不错的起点。此外,substr该函数还可以快速检索长数据的一部分以进行分析。
结合使用“ from_unixtimeand”和“ substris”是一种简单而有效的方法,可以帮助你在原木丛林中找到方向。
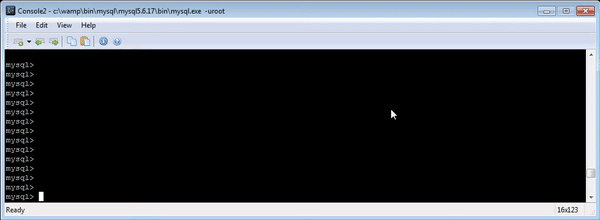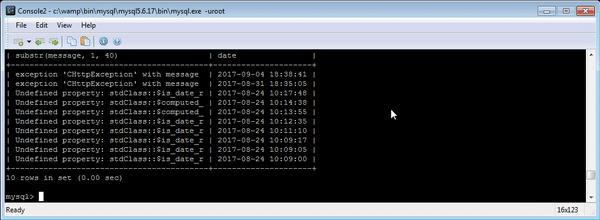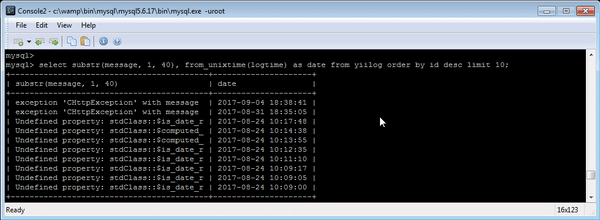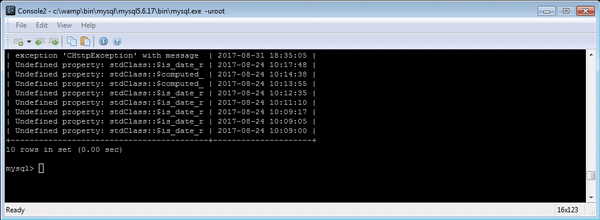
select substr(LOG_COL, 1, 40), from_unixtime(TIME_COL) as date from LOGTABLE order by id desc limit 10;
显示最近 10 条日志,并标注易于理解的时间戳和提取的日志消息开头。
如果您对不同的时间范围感兴趣,可以使用 DATE_SUB 和 DATE_ADD 方法。
例如
select substr(LOG_COL, 1, 40), from_unixtime(TIME_COL) as date from LOGTABLE where from_unixtime(TIME_COL) > '2019-08-24' AND from_unixtime(TIME_COL) < '2019-08-26';
这些指令虽然不能让你立刻成为忍者,但它们是一个很好的基础。
接下来会发生什么?
这只是日志记录这个庞大主题的开端。当你熟悉了本文中介绍的所有概念后,就可以进行更深入的研究了。
诸如配置和使用日志管道之类的主题是您应该进一步学习的内容。当然,这超出了此类入门教程的范围。但是,使用Logstash 和 Kibana等工具可以提升应用程序的质量,因为它们可以帮助您更好地监控应用程序并及时发出任何异常警报。
如果你喜欢这篇文章,不妨了解一下给开发新手的 5 个技巧——我很快会再写一篇关于“反馈循环”主题的详细阐述。
此外,如果您想及时了解我的所有文章,请在推特上关注我。
文章来源:https://dev.to/mfarajewicz/error-logging-patterns-and-practices-2mmo