编写 LINQ to Entities 最佳查询的 8 个技巧和窍门
LINQ是 .NET 应用程序的强大查询工具。编写查询时需要遵循一些技巧,以确保查询快速高效地运行。以下是一些在提升 LINQ to Entities 性能时需要考虑的事项:
- 仅提取所需的列
- 使用 IQueryable 和 Skip/Take
- 在合适的地方使用左连接和内连接
- 使用 AsNoTracking()
- 批量数据插入
- 在实体中使用异步操作
- 查找参数不匹配情况
- 检查提交到数据库的 SQL 查询
仅提取所需的列
使用 LINQ 时,只需在 Select 子句中提取所需的列,而不是加载表中的所有列。
请考虑以下 LINQ 查询。
using (var context = new LINQEntities())
{
var fileCollection = context.FileRepository.Where(a => a.IsDeleted == false).ToList();
}
该查询将被编译成 SQL,如下面的屏幕截图所示。
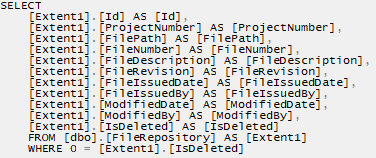
虽然我们可能只需要其中几列,但我们却全部加载了。这会消耗不必要的内存,并降低查询执行速度。我们可以按如下方式修改查询以提高执行效率。
using (var context = new LINQEntities())
{
var fileCollection = context.FileRepository.Where(a => a.IsDeleted == false).
Select(a => new
{
FilePath = a.FilePath
}
).ToList();
}
此查询将以优化的方式编译成 SQL,如下面的屏幕截图所示。

使用 IQueryable 和 Skip/Take
当处理大量数据并将其绑定到表格或网格控件时,我们不应该一次性加载用户的所有记录,因为这会花费很长时间。
相反,我们可以先加载一定数量的记录,比如 10 条或 20 条。当用户想要查看下一组记录时,我们可以按需加载接下来的 10 条或 20 条记录。
C# 中的 IQueryable 类型可以保存未求值的 SQL 查询,这些查询在应用 skip 和 take 后可以转换为针对数据集合运行。
C#
private IEnumerable<object> LoadAllFiles(int skip, int take,string fileRevision,string fileNumber)
{
using (var context = new LINQEntities())
{
//Select and perform join on the needed tables and build an IQueryable collection
IQueryable<FileRepository> fileCollection = context.FileRepository;
//Build queries dynamically over Queryable collection
if(!string.IsNullOrEmpty(fileRevision))
fileCollection = fileCollection.Where(a => a.FileRevision == fileRevision && a.IsDeleted == false);
//Build queries dynamically over Queryable collection
if (!string.IsNullOrEmpty(fileNumber))
fileCollection = fileCollection.Where(a => a.FileRevision == fileNumber && a.IsDeleted == false);
//Apply skip and take and load records
return fileCollection.OrderBy(a=>a.Id).Skip(()=>skip).Take(()=>take).Select(a=>new
{
FileIssuedBy=a.FileIssuedBy
}).ToList();
}
}
SQL
exec sp_executesql N'SELECT
[Project1].[C1] as [C1],
[Project1].[FileIssuedBy] as [FileIssuedBy],
FROM (SELECT
[Extent1].[Id] as [Id],
[Extent1].[FileIssuedBy] as [FileIssuedBy],
1 as [C1]
FROM [dbo].[FileRepository] as [Extent1]
WHERE ([Extent1].[FileRevision] = @p_linq_0) AND (0=[Extent1].[IsDeleted]) AND ([Extent1].[FileRevision] = @p_linq_1)
AND (0=[Extent1].[IsDeleted])) AS [Project1]
ORDER BY row_number() OVER (ORDER BY [Project1].[Id] ASC)
OFFSET @p_linq_2 ROWS FETCH NEXT @p_linq_3 ROWS ONLY ',N'@p_linq_0 nvarchar(4000),@p_linq_1 nvarchar(4000),
@p_linq_2 int,@p_linq_3
int',@p_linq_0=N'A',@p_linq_1=N'A',@p_pinq_2=0,@p_linq_3=10
提示:在编写 LINQ 查询中的 skip 和 take 函数时,为了获得更好的性能,请考虑以下几点:

在合适的地方使用左连接和内连接
左连接和内连接的应用场景在查询执行中起着至关重要的作用。当我们不确定表 A 中的记录在表 B 中是否存在匹配的记录时,应该使用左连接。当我们确定两个表中都存在关联的记录时,应该使用内连接。
选择正确的连接类型来建立表之间的关系非常重要,因为使用内连接查询的多表比使用左连接的多表执行性能更好。
因此,我们应该明确需求,并使用连接(左连接或内连接)来更好地执行查询。
使用 AsNoTracking()
当我们通过 LINQ to Entities 查询从数据库加载记录时,我们会处理这些记录并将其更新回数据库。为此,需要跟踪实体。
当我们只执行读取操作时,不会向数据库发送任何更新,但实体会假定我们会向数据库发送更新并据此进行处理。因此,我们可以使用`AsNoTracking()`来限制实体进行这种假定和处理,从而减少实体需要占用的内存量。
using (var context = new LINQEntities())
{
var fileCollection = context.FileRepository.AsNoTracking().Where(a => a.IsDeleted == false).
Select(a => new
{
FilePath = a.FilePath
}
).ToList();
}
批量数据插入
另一种需要考虑的情况是处理批量数据插入时,例如向 SQL 表中添加数百或数千条记录。
using (var context = new LINQEntities())
{
for(int i=1;i<=1000;i++)
{
var file = new FileRepository { FilePath=""+i+"",FileDescription=""+i+""};
context.FileRepository.Add(file);
}
context.SaveChanges();
}
在前面的代码示例中,每次我们向 FilesRepository 添加新实体时,都会触发Data.Entity.Core中的DetectChanges(),查询执行速度会变慢。
为了解决这个问题,可以使用AddRange 函数,它最适合批量插入数据。AddRange函数在 EF 6.0 中引入,用于在单次数据库往返中完成插入操作,从而降低性能开销。请查看以下修改后的代码。
using (var context = new LINQEntities())
{
var fileCollection = new List<FileRepository>();
for(int i=1;i<=1000;i++)
{
var file = new FileRepository { FilePath=""+i+"",FileDescription=""+i+""};
fileCollection.Add(file);
}
context.FileRepository.AddRange(fileCollection);
context.SaveChanges();
}
在实体中使用异步操作
实体提供以下异步操作:
- ToListAsync(): 异步检索数据集合。
- CountAsync(): 异步检索数据计数。
- FirstAsync(): 异步检索第一个数据集。
- SaveChangesAsync(): 异步保存实体更改。
在应用程序的特定位置使用异步操作,可以减少对 UI 线程的阻塞。它们通过提高 UI 的响应速度来增强 UI 体验。
using (var context = new LINQEntities())
{
var countAsync = context.FileRepository.CountAsync();
var listAsync = context.FileRepository.ToListAsync();
var firstAsync = context.FileRepository.FirstAsync();
context.SaveChangesAsync();
}
查找参数不匹配
查询时数据类型可能不匹配,这通常会导致使用 LINQ to Entities 时耗时过长。例如,假设表中有一个名为FileNumber 的列,其类型为varchar,长度为 10 个字符。因此,它被声明为varchar(10)数据类型。
我们需要加载“File1”中FileNumber字段值匹配的记录。
using (var context = new LINQEntities())
{
string fileNumber = "File1";
var fileCollection = context.FileRepository.Where(a => a.FileNumber == fileNumber).ToList();
}
SQL

在上一张截图中高亮显示的部分,我们可以看到传递的变量在 SQL 中被声明为nvarchar(4000),而表列的类型是varchar(10)。因此,由于参数类型不匹配,SQL 内部会执行类型转换。
为了克服这种参数不匹配的问题,我们需要在属性名称中指定列的类型,如下面的代码所示。
public string FilePath { get; set; }
[Column(TypeName = "varchar")]
public string FileNumber { get; set; }
现在 SQL 参数类型将生成为varchar。
检查提交到数据库的 SQL 查询
在将 SQL 查询提交到数据库之前进行检查,是提升 LINQ to Entities 查询性能最重要的步骤。我们都知道,LINQ to Entities 查询最终会被转换为 SQL 查询,并针对数据库执行。由 LINQ 查询生成的 SQL 查询通常能带来更佳的性能。
我们来看一个例子。考虑以下查询,该查询在 Room、RoomProducts 和 Brands 之间使用了导航 LINQ。
假设以下情况:
- Room表将保存酒店房间列表。
- RoomProducts表将保存Room中的产品列表,并将 Room.Id 作为外键引用。
- Brands表将保存 RoomProducts 品牌,并将 RoomProducts.Id 作为外键引用。
- 这三个表中的记录肯定都包含关联记录。
让我编写一个 LINQ 查询,将所有表通过连接进行映射,并提取匹配的记录。
C#
using (var context = new LINQEntities())
{
var roomCollection = context.Rooms.
Include(x => x.RoomProducts).Select
(x => x.RoomProducts.Select(a => a.Brands)).
ToList();
}
我们正在获取Room、RoomProducts和Brands集合。查询的等效 SQL 代码如下所示。
SQL
SELECT
[Project1].[Id] AS [Id],
[Project1].[C2] AS [C1],
[Project1].[Id1] AS [Id1],
[Project1].[C1] AS [C2],
[Project1].[Id2] AS [Id2],
[Project1].[Brand] AS [Brand],
[Project1].[RoomProductsParentId] AS [RoomProductsParentId],
[Project1].[IsDeleted] AS [IsDeleted],
[Project1].[ModifiedDate] AS [ModifiedDate],
[Project1].[ModifiedBy] AS [ModifiedBy]
FROM ( SELECT
[Extent1].[Id] AS [Id],
[Join1].[Id1] AS [Id1],
[Join1].[Id2] AS [Id2],
[Join1].[Brand] AS [Brand],
[Join1].[RoomProductsParentId] AS [RoomProductsParentId],
[Join1].[IsDeleted1] AS [IsDeleted],
[Join1].[ModifiedDate1] AS [ModifiedDate],
[Join1].[ModifiedBy1] AS [ModifiedBy],
CASE WHEN ([Join1].[Id1] IS NULL) THEN CAST(NULL AS int) WHEN ([Join1].[Id2] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C1],
CASE WHEN ([Join1].[Id1] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Rooms] AS [Extent1]
LEFT OUTER JOIN (SELECT [Extent2].[Id] AS [Id1], [Extent2].[RoomParentId] AS [RoomParentId], [Extent3].[Id] AS [Id2], [Extent3].[Brand] AS [Brand], [Extent3].[RoomProductsParentId] AS [RoomProductsParentId], [Extent3].[IsDeleted] AS [IsDeleted1], [Extent3].[ModifiedDate] AS [ModifiedDate1], [Extent3].[ModifiedBy] AS [ModifiedBy1]
FROM [dbo].[RoomProducts] AS [Extent2]
LEFT OUTER JOIN [dbo].[Brands] AS [Extent3] ON [Extent2].[Id] = [Extent3].[RoomProductsParentId] ) AS [Join1] ON [Extent1].[Id] = [Join1].[RoomParentId]
) AS [Project1]
ORDER BY [Project1].[Id] ASC, [Project1].[C2] ASC, [Project1].[Id1] ASC, [Project1].[C1] ASC
我们可以看到,作为导航属性一部分生成的查询使用左外连接来建立表之间的关系,并加载所有列。与内连接查询相比,由左外连接构成的查询运行速度较慢。
既然我们知道这三个表之间肯定存在关联,那么让我们稍微修改一下这个查询。
C#
using (var context = new LINQEntities())
{
var roomCollection = (from room in context.Rooms
join products in context.RoomProducts on room.Id equals products.RoomParentId
join brands in context.Brands on products.Id equals brands.RoomProductsParentId
select new
{
Room = room.Room,
Product = products.RoomProduct,
Brand = brands.Brand
}).ToList();
}
这将产生以下结果:
SQL
SELECT
[Extent1].[Id] AS [Id],
[Extent1].[Room] AS [Room],
[Extent2].[RoomProduct] AS [RoomProduct],
[Extent3].[Brand] AS [Brand]
FROM [dbo].[Rooms] AS [Extent1]
INNER JOIN [dbo].[RoomProducts] AS [Extent2] ON [Extent1].[Id] = [Extent2].[RoomParentId]
INNER JOIN [dbo].[Brands] AS [Extent3] ON [Extent2].[Id] = [Extent3].[RoomProductsParentId]
现在代码看起来更简洁,执行速度也比我们之前的尝试更快。
结论
在这篇博文中,我们探讨了一些可以着重提升 LINQ to Entities 性能的方面。希望本文对您有所帮助。
Syncfusion 提供超过 1000 个自定义控件,旨在简化开发人员在各种平台上的工作。请查看并在您的应用程序开发中使用它们:
如果您对我们的组件有任何疑问或需要澄清,请在下方评论区留言。您也可以通过我们的支持论坛、Direct-Trac或反馈门户联系我们。我们很乐意为您提供帮助!
文章《编写 LINQ to Entities 最佳查询的 8 个技巧和窍门》最初发表于Syncfusion 博客。
文章来源:https://dev.to/syncfusion/8-tips-and-tricks-for-writing-the-best-queries-in-linq-to-entities-20c0