Node.js 设计模式:实用指南
由 Mux 主办的 DEV 全球展示挑战赛:展示你的项目!

无论软件开发人员是否意识到,设计模式都是他们日常工作的一部分。
在本文中,我们将探讨如何在实际应用中识别这些模式,并探讨如何开始在自己的项目中使用它们。
什么是设计模式?
简而言之,设计模式是一种组织解决方案代码的方式,它可以帮助你获得某些好处,例如更快的开发速度、代码重用性等等。
所有模式都非常容易融入面向对象编程(OOP)范式。不过,鉴于 JavaScript 的灵活性,你也可以在非 OOP 项目中实现这些概念。
说到设计模式,数量实在太多,一篇文章根本无法全部涵盖。事实上,已经有专门的书籍探讨这个主题,而且每年都会出现新的模式,使得现有的书籍列表无法全部涵盖。
模式的一种非常常见的分类是GoF 书(四人帮之书)中使用的分类,但由于我只会回顾其中的一小部分,所以我将忽略这种分类,而只是向您展示一个您可以立即在代码中看到并开始使用的模式列表。
立即调用函数表达式 (IIFE)
我要展示的第一个模式允许你同时定义和调用一个函数。由于 JavaScript 的作用域机制,使用立即执行函数表达式 (IIFE) 可以很好地模拟类中的私有属性等功能。事实上,这种模式有时是其他更复杂模式的必要组成部分。我们稍后会详细介绍。
IIFE 是什么样的?
但在深入探讨其应用案例和背后的机制之前,让我先快速地向您展示一下它的实际外观:
(function() {
var x = 20;
var y = 20;
var answer = x + y;
console.log(answer);
})();
将上述代码粘贴到 Node.js REPL 甚至浏览器的控制台中,即可立即获得结果,因为正如其名称所示,您在定义函数后立即执行了该函数。
即时函数表达式 (IIFE) 的模板由一个匿名函数声明、一组括号(将定义转换为函数表达式,即赋值语句)以及末尾的一组调用括号组成。如下所示:
(function(/*received parameters*/) {
//your code here
})(/*parameters*/)
用例
虽然这听起来可能很疯狂,但实际上使用即时函数表达式(IIFE)也有一些好处和应用场景,例如:
模拟静态变量
还记得静态变量吗?比如在 C 或 C# 等其他语言中。如果你不熟悉静态变量,简单来说,静态变量会在第一次使用时初始化,之后会一直使用上次赋值的值。它的好处在于,如果你在函数内部定义一个静态变量,那么无论调用该函数多少次,这个变量对函数的所有实例都是通用的,因此可以大大简化类似这样的情况:
function autoIncrement() {
static let number = 0
number++
return number
}
上述函数每次调用都会返回一个新的数字(当然,前提是 JavaScript 中可以使用 static 关键字)。我们确实可以用 JavaScript 的生成器来实现这一点,但假设我们无法使用生成器,你可以像这样模拟一个静态变量:
let autoIncrement = (function() {
let number = 0
return function () {
number++
return number
}
})()
你在这里看到的,是闭包的魔力,它被封装在一个立即执行函数表达式(IIFE)中。简直太神奇了。你实际上是返回了一个新函数,这个函数会被赋值给autoIncrement变量(这要归功于IIFE的实际执行)。而且,由于JavaScript的作用域机制,你的函数始终可以访问这个数字变量(就像它是一个全局变量一样)。
模拟私有变量
你可能已经知道(也可能不知道),ES6 类将所有成员都视为公共成员,这意味着没有私有属性或方法。这显然是不可能的,但借助立即执行函数表达式 (IIFE),如果你愿意,理论上可以模拟私有成员的情况。
const autoIncrementer = (function() {
let value = 0;
return {
incr() {
value++
},
get value() {
return value
}
};
})();
> autoIncrementer.incr()
undefined
> autoIncrementer.incr()
undefined
> autoIncrementer.value
2
> autoIncrementer.value = 3
3
> autoIncrementer.value
2
上面的代码展示了一种实现方法。虽然你没有明确定义一个可以随后实例化的类,但请注意,你定义了一个结构,一组属性和方法,它们可以使用你正在创建的对象共有的变量,但这些变量无法从外部访问(如赋值失败所示)。
工厂方法模式
我尤其喜欢这种模式,因为它能帮助你更好地清理代码。
本质上,工厂方法允许你将创建对象的逻辑(即创建哪个对象以及为什么创建)集中在一个地方。这样,你就可以忽略这部分细节,专注于请求所需的对象并使用它。
这看起来似乎只是一个很小的好处,但请稍等片刻,相信我,你会明白的。
工厂化生产模式是什么样的?
如果先观察这种模式的用法,再观察其实现方式,就更容易理解了。
以下是一个例子:
( _ => {
let factory = new MyEmployeeFactory()
let types = ["fulltime", "parttime", "contractor"]
let employees = [];
for(let i = 0; i < 100; i++) {
employees.push(factory.createEmployee({type: types[Math.floor( (Math.random(2) * 2) )]}) )}
//....
employees.forEach( e => {
console.log(e.speak())
})
})()
从上面的代码中可以得出的关键信息是,你正在向同一个数组中添加对象,所有这些对象都共享同一个接口(因为它们具有相同的方法集),但你实际上不需要关心要创建哪个对象以及何时创建。
现在你可以看看实际的实现过程,正如你所看到的,有很多东西需要注意,但它其实很简单:
class Employee {
speak() {
return "Hi, I'm a " + this.type + " employee"
}
}
class FullTimeEmployee extends Employee{
constructor(data) {
super()
this.type = "full time"
//....
}
}
class PartTimeEmployee extends Employee{
constructor(data) {
super()
this.type = "part time"
//....
}
}
class ContractorEmployee extends Employee{
constructor(data) {
super()
this.type = "contractor"
//....
}
}
class MyEmployeeFactory {
createEmployee(data) {
if(data.type == 'fulltime') return new FullTimeEmployee(data)
if(data.type == 'parttime') return new PartTimeEmployee(data)
if(data.type == 'contractor') return new ContractorEmployee(data)
}
}
用例
前面的代码已经展示了一个通用的用例,但如果我们想要更具体一些,我喜欢用这种模式来处理错误对象的创建。
想象一下,你有一个 Express 应用,它有大约 10 个接口,每个接口都需要根据用户输入返回两到三个错误。这意味着你需要编写 30 行类似以下的语句:
if(err) {
res.json({error: true, message: “Error message here”})
}
这本来没什么问题,除非下次你需要突然给错误对象添加一个新属性。这时你就得遍历整个项目,修改所有 30 个地方。而解决这个问题的方法是把错误对象的定义移到一个类里。这当然很好,除非你有多个错误对象,这时你就得根据只有你自己知道的逻辑来决定实例化哪个对象。明白我的意思了吗?
如果将创建错误对象的逻辑集中化,那么在你的代码中,你只需要做类似这样的事情:
if(err) {
res.json(ErrorFactory.getError(err))
}
好了,完成了,以后再也不用修改那一行了。
单例模式
这虽然是个老套但依然有效的模式,但它非常简单,却能帮助你追踪类实例的数量。实际上,它能确保实例数量始终只有一个。单例模式的主要优势在于,它允许你实例化一个对象一次,然后在每次需要时都使用它,而无需创建新的实例,也无需维护对它的引用,无论是全局引用还是作为依赖项传递。
单例模式是什么样的?
通常,其他语言会使用单个静态属性来实现这种模式,并在实例创建后将其存储起来。问题在于,正如我之前提到的,我们在 JavaScript 中无法访问静态变量。因此,我们可以通过两种方式来实现,一种是使用立即执行函数表达式 (IIFE) 而不是类。
另一种方法是使用 ES6 模块,并让我们的单例类使用一个局部全局变量来存储实例。这样一来,类本身会被导出到模块之外,但全局变量仍然只在模块内部有效。
我知道,但相信我,这听起来比看起来要复杂得多:
let instance = null
class SingletonClass {
constructor() {
this.value = Math.random(100)
}
printValue() {
console.log(this.value)
}
static getInstance() {
if(!instance) {
instance = new SingletonClass()
}
return instance
}
}
module.exports = SingletonClass
你可以这样使用它:
const Singleton = require(“./singleton”)
const obj = Singleton.getInstance()
const obj2 = Singleton.getInstance()
obj.printValue()
obj2.printValue()
console.log("Equals:: ", obj === obj2)
当然,最终结果如下:
0.5035326348000628
0.5035326348000628
Equals:: true
确认确实如此,我们只实例化对象一次,并返回已存在的实例。
用例
在决定是否需要单例模式时,你需要考虑一个问题:你真正需要多少个类的实例?如果答案是 2 个或更多,那么这种模式就不适合你。
但有时在处理数据库连接时,您可能需要考虑一下。
想想看,一旦连接到数据库,最好在整个代码中保持连接畅通。当然,这有很多种解决方法,但这种模式确实是其中之一。
以上述例子为例,我们可以将其推导出如下形式:
const driver = require("...")
let instance = null
class DBClass {
constructor(props) {
this.properties = props
this._conn = null
}
connect() {
this._conn = driver.connect(this.props)
}
get conn() {
return this._conn
}
static getInstance() {
if(!instance) {
instance = new DBClass()
}
return instance
}
}
module.exports = DBClass
现在,您可以确信,无论您身在何处,只要使用 getInstance 方法,您都将返回唯一的活动连接(如果有的话)。
观察者模式
这种模式非常有趣,因为它允许你对特定输入做出被动响应,而不是主动检查输入是否已提供。换句话说,使用这种模式,你可以指定要等待的输入类型,然后被动地等待该输入提供后再执行代码。你可以把它理解为一种“设置好就不用管”的方法。
在这里,观察者就是你的对象,它们知道想要接收的输入类型以及要采取的行动,它们的目的是“观察”另一个对象并等待它与自己进行交流。
另一方面,可观察对象会在有新输入可用时通知观察者,以便它们在必要时做出反应。如果这听起来很熟悉,那是因为它确实如此,Node 中所有处理事件的东西都在使用这种模式。
观察者模式是什么样的?
你有没有自己写过HTTP服务器?类似这样的:
const http = require('http');
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Your own server here');
});
server.on('error', err => {
console.log(“Error:: “, err)
})
server.listen(3000, '127.0.0.1', () => {
console.log('Server up and running');
});
在上面的代码中,你其实看到了观察者模式的实际应用。至少,它是一种实现方式。你的服务器对象充当可观察对象,而你的回调函数则是真正的观察者。这里类似事件的接口(见粗体代码)、`on` 方法以及事件名称可能会让理解变得有些复杂,但请考虑以下实现:
class Observable {
constructor() {
this.observers = {}
}
on(input, observer) {
if(!this.observers[input]) this.observers[input] = []
this.observers[input].push(observer)
}
triggerInput(input, params) {
this.observers[input].forEach( o => {
o.apply(null, params)
})
}
}
class Server extends Observable {
constructor() {
super()
}
triggerError() {
let errorObj = {
errorCode: 500,
message: 'Port already in use'
}
this.triggerInput('error', [errorObj])
}
}
现在,您可以再次以完全相同的方式设置同一个观察者:
server.on('error', err => {
console.log(“Error:: “, err)
})
如果你调用 triggerError 方法(该方法旨在向你展示如何让观察者知道有新的输入),你会得到完全相同的输出:
Error:: { errorCode: 500, message: 'Port already in use' }
如果您打算在 Node.js 中使用此模式,请先查看EventEmitter对象,因为它是 Node.js 对此模式的实现,可能会为您节省一些时间。
用例
正如你可能已经猜到的,这种模式非常适合处理异步调用,因为从外部请求获取响应可以被视为一个新的输入。而Node.js中,我们又怎能少了源源不断的异步代码涌入项目呢?所以,下次当你需要处理异步场景时,不妨考虑一下这种模式。
正如你所见,这种模式的另一个广泛应用场景是触发特定事件。任何容易异步触发事件(例如错误或状态更新)的模块都可以使用这种模式。例如,HTTP 模块、任何数据库驱动程序,甚至socket.io都允许你为从代码外部触发的特定事件设置观察者。
责任链
责任链模式是许多Node.js开发者在不知不觉中使用过的模式。
它指的是以一种能够将请求发送者与能够满足该请求的对象解耦的方式来构建你的代码。换句话说,假设对象 A 发送请求 R,可能有三个不同的接收对象 R1、R2 和 R3,那么 A 如何知道应该将 R 发送给哪个对象呢?A 需要关心这个问题吗?
最后一个问题的答案是:不,它不应该。所以,如果A不应该关心谁来处理这个请求,为什么不让R1、R2和R3自己决定呢?
这就是责任链发挥作用的地方,我们创建了一条接收对象的链条,这些对象会尝试满足请求,如果无法满足,它们就会将请求传递给下一个对象。听起来是不是很熟悉?
责任链是怎样的?
这是该模式的一个非常基本的实现,如底部所示,我们有四个可能的值(或请求)需要处理,但我们并不关心由谁来处理它们,我们只需要至少一个函数来使用它们,因此我们只是将它们发送到链中,让每个函数决定是否应该使用它或忽略它。
function processRequest(r, chain) {
let lastResult = null
let i = 0
do {
lastResult = chain[i](r)
i++
} while(lastResult != null && i < chain.length)
if(lastResult != null) {
console.log("Error: request could not be fulfilled")
}
}
let chain = [
function (r) {
if(typeof r == 'number') {
console.log("It's a number: ", r)
return null
}
return r
},
function (r) {
if(typeof r == 'string') {
console.log("It's a string: ", r)
return null
}
return r
},
function (r) {
if(Array.isArray(r)) {
console.log("It's an array of length: ", r.length)
return null
}
return r
}
]
processRequest(1, chain)
processRequest([1,2,3], chain)
processRequest('[1,2,3]', chain)
processRequest({}, chain)
输出结果为:
It's a number: 1
It's an array of length: 3
It's a string: [1,2,3]
Error: request could not be fulfilled
用例
在我们的生态系统中,这种模式最明显的例子就是ExpressJS 的中间件。使用这种模式,你实际上是在设置一系列函数(中间件),这些函数会评估请求对象,并决定是否对其执行操作。你可以把这种模式看作是上述示例的异步版本,只不过这里你检查的不是函数是否返回值,而是传递给下一个回调函数的值。
var app = express();
app.use(function (req, res, next) {
console.log('Time:', Date.now());
next(); //call the next function on the chain
});
中间件是这种模式的一种特殊实现,因为并非只有链中的一个成员才能满足请求,而是所有成员都可以做到。尽管如此,其背后的基本原理仍然相同。
最后想说的
以上只是你可能每天都会遇到却不自知的几种模式。我鼓励你研究一下其他的模式,即使你现在找不到直接的应用场景,既然我已经向你展示了其中一些模式在实际应用中的样子,你或许就能自己发现它们了!希望这篇文章能让你对这个主题有所启发,并帮助你更快地提升编码技能。下次见!
插件:LogRocket,一款用于 Web 应用的 DVR
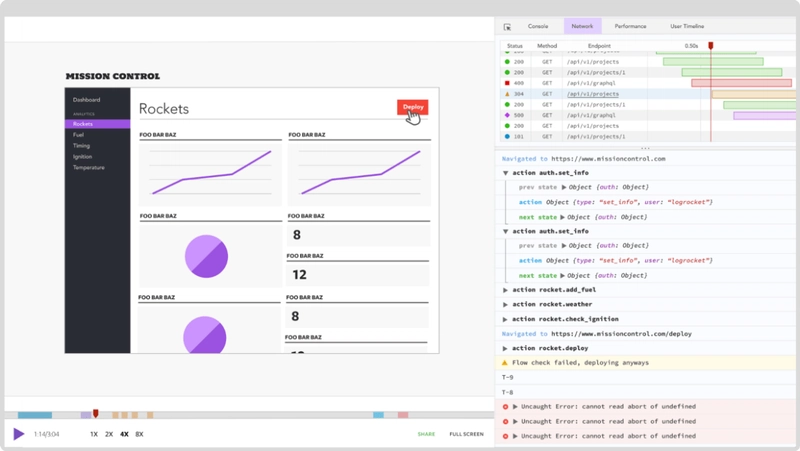
LogRocket是一款前端日志工具,可让您重现问题,如同在您自己的浏览器中发生一样。无需猜测错误原因,也无需用户提供屏幕截图和日志转储,LogRocket 即可让您重现会话,快速了解问题所在。它与任何框架的应用程序完美兼容,并提供插件来记录来自 Redux、Vuex 和 @ngrx/store 的额外上下文信息。
除了记录 Redux 操作和状态之外,LogRocket 还会记录控制台日志、JavaScript 错误、堆栈跟踪、包含标头和正文的网络请求/响应、浏览器元数据以及自定义日志。它还会对 DOM 进行插桩,记录页面上的 HTML 和 CSS,即使是最复杂的单页应用程序,也能生成像素级精确的视频。
免费试用。
文章《Node.js 设计模式:实用指南》最初发表于LogRocket 博客。
文章来源:https://dev.to/bnevilleoneill/design-patterns-in-node-js-a-practical-guide-4bmk