利用句法分析树进行语法根源分析
科技世界中充斥着各种各样的抽象概念,有时难免让人感到不知所措。当你试图理解一种新的范式,或者试图解开一个或多个难以理解的概念时,这种感觉尤为强烈。
在学习计算机科学的背景下,抽象概念实在太多,我们不可能全部了解、看到或识别它们——更不用说理解它们了!
抽象概念的力量在于能够透过它们看到本质,理解事物是如何被抽象化的以及为什么被抽象化,这能让你成为更优秀的程序员。然而,同样地,每一种抽象概念的产生都有其原因:那就是为了让我们不必每天都为它们操心!我们不应该时时刻刻都想着抽象概念,而且大多数情况下,我们也确实很少这样做。但关键在于——有些抽象概念比其他的更重要。大多数工程师最关心的可能是他们如何与计算机通信,以及计算机如何理解他们的代码。即使我们永远不需要编写冒泡排序算法,只要我们编写代码,就必须与机器进行交互。
好了,现在终于到了我们揭开这些谜团,了解程序员工作流程背后的抽象概念的时候了。
解析解析的含义
树形数据结构在我们计算机科学的探索之旅中不断出现。我们见过它被用来存储各种类型的数据,见过自平衡的树形结构,也见过针对空间和存储处理进行优化的树形结构。我们甚至研究过如何通过旋转和重新着色来操纵树形结构,使其符合一系列规则。
尽管数据结构种类繁多,但我们尚未发现一种特殊的树形数据结构。即使我们对计算机科学一无所知,不知道如何平衡树,甚至不知道树形数据结构的工作原理,所有程序员每天都会接触到一种树形结构,原因很简单:每个编写代码的开发者都需要确保他们的代码能够被机器理解。
这种数据结构称为解析树,它是底层抽象之一,使得我们程序员编写的代码能够被计算机“读取”。

从本质上讲,句法分析树是用图示的方式展现句子的语法结构。句法分析树起源于语言学领域,但也应用于教学法(即教学研究)。句法分析树常用于教学生识别句子成分,也是引入语法概念的常用方法。我们很可能都曾接触过句法分析树,例如在小学时就学习过句子图解。
句法分析树实际上只是句子的“图解”形式;该句子可以用任何语言写成,这意味着它可以遵循任何一套语法规则。
句子图解是指将一个句子分解成最小、最独立的组成部分。如果我们从句子图解的角度来思考句法分析树,我们会很快意识到,根据句子的语法和语言,句法分析树实际上可以用多种不同的方式构建!
但是,计算机版本的“句子”究竟是什么?我们又该如何准确地将其绘制成图呢?
最好先从我们已经熟悉的例子入手,所以让我们通过绘制一个普通英语句子的图解来唤起记忆。

如图所示,我们有一个简单的句子:“Vaidehi 吃了馅饼”。由于我们知道句法分析树本质上就是一个句子的图解,所以我们可以根据这个例句构建一个句法分析树。记住,我们实际上要做的就是确定这个句子的各个组成部分,并将其分解成最小、最独立的部分。
我们可以先将句子拆分成两部分:名词“Vaidehi”和动词短语“ate the pie”。由于名词无法进一步拆分,我们将保留“Vaidehi”这个词。换句话说,既然名词无法进一步拆分,那么它就不会衍生出任何子节点。
那么动词短语“ate the pie”呢?嗯,这个短语还没有被分解成最简单的形式,对吧?我们可以进一步剖析它。首先,“ate”是一个动词,而“the pie”更像是一个名词——更准确地说,它是一个名词短语。如果我们把“ate the pie”拆开,就可以把它分成动词和名词短语。由于动词无法用更详细的结构图来表示,所以“ate”在我们的句法分析树中会成为一个叶节点。
好了,现在只剩下名词短语“馅饼”了。我们可以把这个短语分成两个部分:名词“馅饼”和它的限定词,限定词就是修饰名词的词。在这个例子中,限定词是“the”。
一旦我们将名词短语拆分完毕,句子拆分也就完成了!换句话说,我们的句法分析树图就绘制完成了。当我们查看句法分析树时,会发现句子读起来仍然一样,我们实际上并没有改变它。我们只是将给定的句子,运用英语语法规则,将其拆分成最小、最独立的部分。
以英语为例,每个句子的最小“组成部分”是单词;单词可以组合成短语,例如名词短语或动词短语,而这些短语又可以与其他短语组合,从而构成句子表达。

然而,这只是一个例子,说明如何将一种特定语言中一个特定句子及其自身的语法规则绘制成句法分析树。同一个句子在另一种语言中会呈现出截然不同的面貌,尤其当它必须遵循自身独特的语法规则时。
最终,一种语言的语法和句法——包括该语言的句子结构——成为决定该语言如何定义、我们如何用它写作以及我们这些说这种语言的人最终如何理解和解释它的规则。
有趣的是,我们之所以知道如何分析“Vaidehi ate the pie”这个简单句,是因为我们已经熟悉英语语法。想象一下,如果我们的句子缺少一个名词或一个动词会怎样?我们很可能第一次读到这个句子时就会很快意识到它根本就不是一个完整的句子!相反,我们读完后几乎立刻就会发现,这是一个句子片段,或者说句子的一部分。
然而,我们之所以能够识别句子片段,唯一的原因是我们了解英语的语言规则——即(几乎)每个句子都需要名词和动词才能有效。语言的语法就是我们检验一个句子在该语言中是否有效的方法;这种“检验”有效性的过程被称为句子解析。
当我们第一次阅读一个句子并理解它时,解析句子的过程与绘制句子图的过程涉及相同的心理步骤,而绘制句子图又与构建句法分析树的过程涉及相同的步骤。当我们第一次阅读一个句子时,我们实际上是在进行对它的心理解构和解析。
事实证明,计算机对我们编写的代码也做着完全相同的事情!
解析表达式就像是我们的职责一样
好了,我们现在知道如何绘制和解析英语句子。但这如何应用于代码呢?在我们的代码中,“句子”究竟是什么?
我们可以把语法分析树想象成代码结构的图示。如果我们把代码、程序,甚至是最简单的脚本想象成一个句子,我们很快就会意识到,我们编写的所有代码实际上都可以简化成一系列表达式。
举个例子更容易理解,所以我们来看一个非常简单的计算器程序。我们可以使用数学的语法“规则”,通过一个简单的表达式来构建解析树。我们需要找到表达式中最简单、最独立的单元,这意味着我们需要将表达式分解成更小的部分,如下图所示。
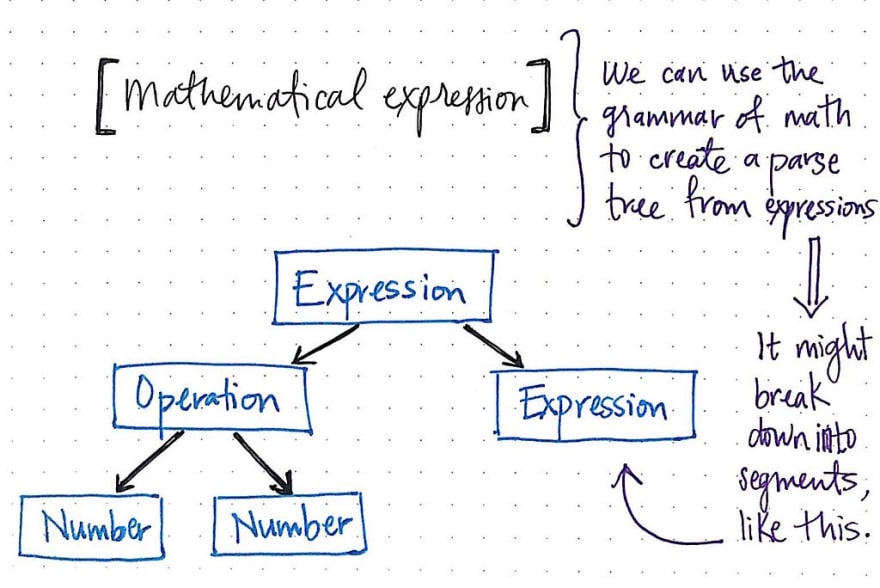
我们会注意到,一个数学表达式有它自己的语法规则要遵循;即使是一个简单的表达式(比如两个数相乘,然后加到另一个数上),也可以分解成更简单的表达式。
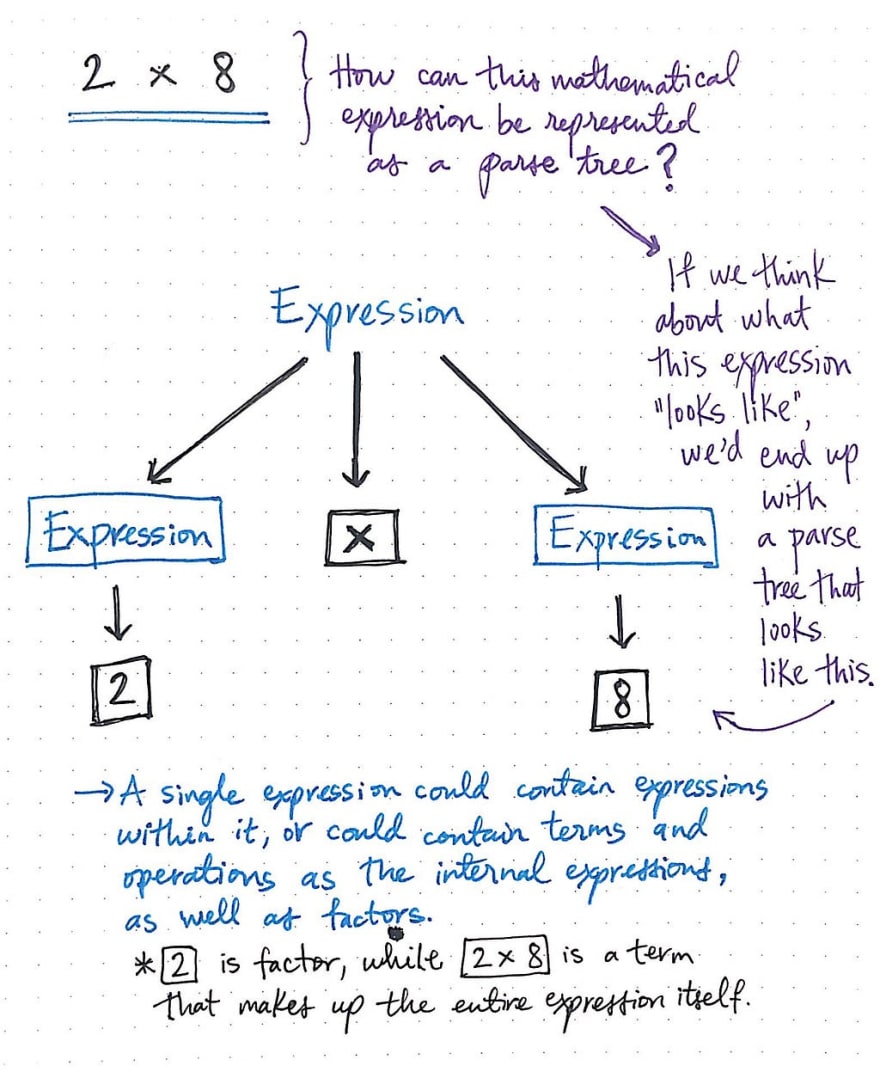
但我们先从一个简单的计算开始。我们如何用数学语法为像 2 x 8 这样的表达式创建语法分析树呢?
如果我们仔细想想这个表达式到底是什么样子,就会发现它由三个不同的部分组成:左边的表达式、右边的表达式,以及将这两个表达式相乘的运算。
图中所示为表达式 2 x 8 的语法分析树图。我们可以看到,运算符 x 是表达式中无法进一步简化的部分,因此它没有任何子节点。
左边和右边的表达式可以简化为具体的项,即 2 和 8。就像我们之前看到的英语句子示例一样,一个数学表达式可以包含内部表达式,以及单独的项,例如短语 2 x 8,或者因子,例如数字 2 本身。
但是,在我们创建这个句法分析树之后会发生什么呢?我们会注意到,这里的子节点层级结构不如之前的句子示例中那么明显。节点 2 和 8 都处于同一层级,那么我们该如何解释这种情况呢?
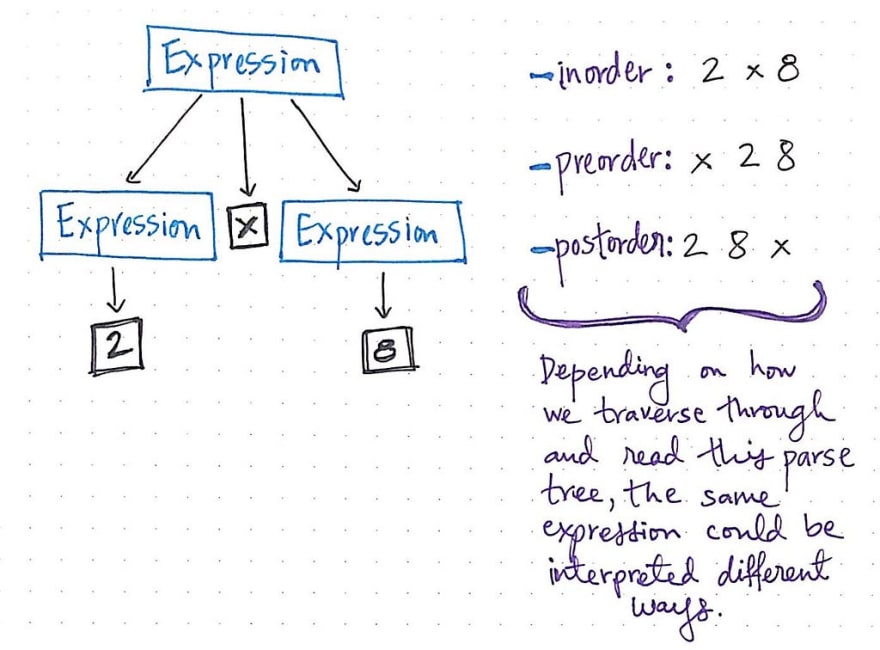
我们已经知道,遍历树有多种不同的深度优先遍历方法。根据遍历方式的不同,数学表达式 2 × 8 可以有多种解释和解读。例如,如果我们使用中序遍历,我们会先读取左树,然后是根节点,最后是右树,结果为 2 -> x -> 8。
但是,如果我们选择使用前序遍历来遍历这棵树,我们会先读取根节点的值,然后读取左子树的值,最后读取右子树的值,结果为 x -> 2 -> 8。如果我们使用后序遍历,我们会读取左子树的值,读取右子树的值,最后读取根节点的值,结果为 2 -> 8 -> x。
语法分析树向我们展示了表达式的结构,揭示了表达式的具体语法,这意味着同一个“句子”可以用多种不同的方式表达。因此,语法分析树也常被称为具体语法树,简称CST。当机器解释或“读取”这些树时,必须严格按照规则进行解析,才能最终得到正确的表达式,并且所有项的顺序和位置都正确无误!
但我们处理的大多数表达式都比 2 × 8 复杂得多。即使是计算器程序,我们也可能需要进行更复杂的计算。例如,如果我们想求解像 5 + 1 × 12 这样的表达式,会发生什么?我们的语法分析树会是什么样子?
事实证明,解析树的问题在于,有时你可能会得到多个解析树。

更具体地说,一个表达式在解析时可能存在多个结果。如果我们假设解析树是从最底层开始读取的,那么我们就能理解叶节点的层级结构如何导致同一个表达式被解释成两种截然不同的结果,从而产生两个完全不同的值。
例如,在上图中,表达式 5 + 1 × 12 有两种可能的语法分析树。正如我们在左侧的语法分析树中看到的,节点的层级结构决定了表达式 1 × 12 会先被计算,然后继续进行加法运算:5 + (1 × 12)。另一方面,右侧的语法分析树则截然不同;节点的层级结构强制先进行加法运算 (5 + 1),然后沿着树向上移动以继续进行乘法运算:(5 + 1) × 12。
语言中的语法歧义正是造成这种情况的原因:当语法树的构造方式不明确时,至少可以用多种方式来构造它。
但问题在于:语法歧义对编译器来说是个问题!

根据我们大多数人在学校学到的数学规则,我们理所当然地知道乘法应该总是在加法之前进行。换句话说,根据数学语法,上面例子中只有左侧的语法树才是正确的。记住:语法定义了任何语言的句法和规则,无论是英语句子还是数学表达式。
但编译器究竟是如何自然而然地知道这些规则的呢?它根本不可能做到!如果我们不提供语法规则,编译器就无法知道该如何解读我们编写的代码。例如,如果编译器看到我们编写了一个数学表达式,而这个表达式可能会生成两种不同的语法分析树,它就不知道该选择哪一种,因此,它甚至不知道该如何读取或解释我们的代码。
正因如此,大多数编程语言通常会避免使用歧义语法。事实上,大多数解析器和编程语言从一开始就会有意处理歧义问题。编程语言通常会采用强制执行优先级的语法,这将强制某些操作或符号比其他操作或符号具有更高的权重/价值。例如,确保在构建语法分析树时,乘法运算的优先级高于加法运算,从而保证最终只能构建出一个语法分析树。
另一种解决歧义问题的方法是强制执行语法解释方式。例如,在数学中,如果我们有一个表达式 1 + 2 + 3 + 4,我们自然知道应该从左边开始向右加。如果我们希望编译器理解如何用我们自己的代码实现这一点,就需要强制执行左结合律,这将限制编译器,使其在解析代码时,生成的解析树中因子 4 的位置低于因子 1。
这两个例子通常被称为编译器设计中的消除歧义规则,因为它们创建了特定的语法规则,确保我们永远不会得到会让编译器感到非常困惑的歧义语法。
一份我(对我的解析器)的爱意。
如果歧义是语法树所有弊端的根源,那么清晰性显然是首选的操作模式。当然,我们可以添加消除歧义的规则来避免出现歧义的情况,以免我们的小计算机在读取代码时束手无策,但实际上我们做的远不止这些。或者更确切地说,真正承担重任的是我们使用的编程语言!
让我解释一下。我们可以这样理解:使数学表达式更清晰的方法之一就是使用括号。事实上,对于我们之前处理的表达式:5 + 1 × 12,我们大多数人可能都会这样做。我们读完这个表达式后,可能会想起在学校学过的运算顺序,在脑海中将其改写为:5 + (1 × 12)。括号 () 帮助我们更清晰地理解表达式本身,以及其中固有的两个表达式。这两个符号对我们来说是可识别的,如果我们将它们放入语法树中,它们不会有任何子节点,因为它们无法进一步分解。
这些就是我们所说的终结符,也常被称为标记。它们对所有编程语言都至关重要,因为它们帮助我们理解表达式各部分之间的关系,以及各个元素之间的语法关系。编程中一些常见的标记包括运算符(+、-、×、/)、括号(())和保留条件词(if、then、else、end)。有些标记用于帮助阐明表达式,因为它们可以明确不同元素之间的关系。

那么,我们的语法分析树中还有哪些其他内容呢?显然,我们的代码中不仅仅只有 if 语句和加号!我们通常还需要处理非终结符集合,这些非终结符是表达式、项和因子,它们有可能被进一步分解。这些短语/概念内部包含其他表达式,例如表达式 (8 + 1) / 3。
终结符和非终结符都与它们在语法分析树中的位置有着特定的关系。顾名思义,终结符总是会出现在语法分析树的叶节点上;这意味着不仅运算符、括号和保留条件语句是“终结符”,而且代表每个叶节点上的字符串、数字或概念的所有因子值也都是终结符。任何被分解成最小组成部分的东西,实际上总是“终结符”。
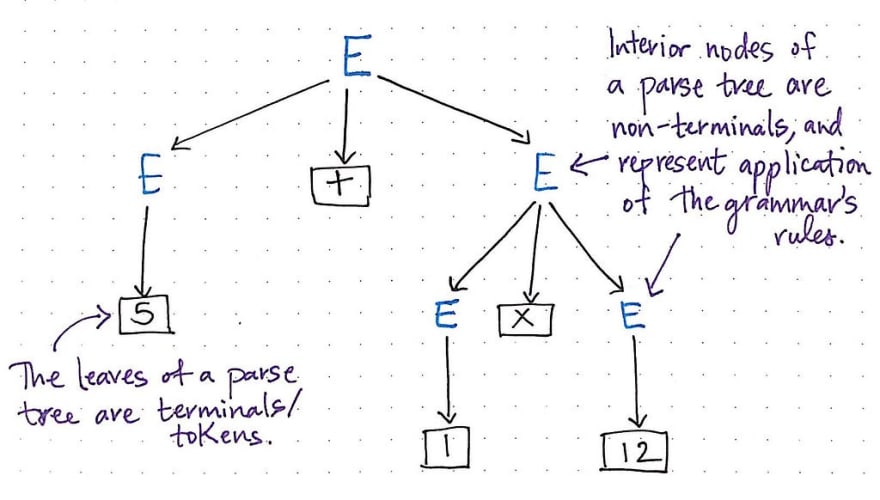
另一方面,语法分析树的内部节点——即父节点(非叶子节点)——是非终结符,它们代表了编程语言语法规则的应用。
一旦我们理解了解析树只不过是程序及其所有符号、概念和表达式的表示,那么解析树就更容易理解、可视化和识别了。
但是,语法分析树的价值究竟是什么呢?作为程序员,我们通常不会去想这个问题,但它的存在肯定有其原因,对吧?

事实证明,最关心解析树的是解析器,它是编译器的一部分,负责处理解析我们编写的所有代码的过程。
解析过程实际上就是接收一些输入,并从中构建一个解析树。这些输入可以是多种不同的内容,例如字符串、句子、表达式,甚至是整个程序。
无论我们输入什么,解析器都会将输入解析成语法短语,并据此构建解析树。在我们的计算机和编译过程中,解析器主要扮演两个角色:
- 给定一个有效的标记序列,它必须能够按照该语言的语法生成相应的解析树。
- 当给定无效的标记序列时,它应该能够检测到语法错误,并告知编写代码的程序员其代码中存在的问题。
就是这样!这听起来可能很简单,但如果我们开始考虑一些程序的规模和复杂性,我们很快就会意识到,为了让解析器真正履行这两个看似简单的角色,需要对事物进行多么明确的定义。
例如,即使是一个简单的解析器,也需要做很多工作才能处理像 1 + 2 + 3 x 4 这样的表达式的语法。
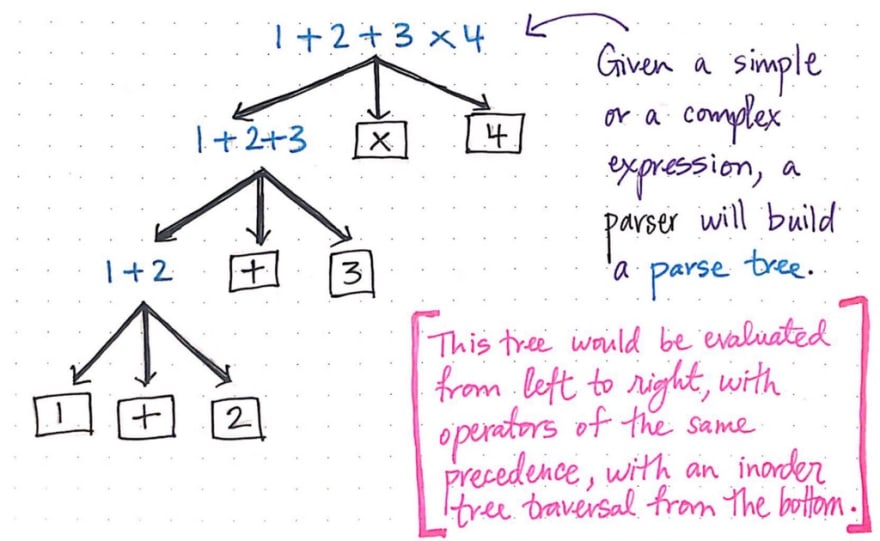
- 首先,它需要根据这个表达式构建一个解析树。解析器接收到的输入字符串可能没有显示任何操作之间的关联,但解析器需要构建一个能够显示这些关联关系的解析树。
- 但是,为了做到这一点,它需要知道该语言的语法和要遵循的语法规则。
- 一旦它能够真正创建一个(没有歧义的)语法分析树,它就需要能够提取标记和非终结符,并排列它们,使语法分析树的层次结构正确。
- 最后,解析器需要确保在评估这棵树时,从左到右进行评估,并且运算符的优先级相同。
- 但是等等!它还需要确保,当使用中序遍历方法从底部遍历这棵树时,不会出现任何语法错误!
- 当然,如果解析器出错,它需要查看输入,找出出错的地方,然后告诉程序员。
如果这感觉工作量巨大,那是因为它确实如此。但别太担心要完成所有工作,因为那是解析器的工作,而且大部分工作都已被抽象化。幸运的是,解析器会得到编译器其他部分的帮助。下周我们将详细介绍!
资源
幸运的是,几乎所有计算机科学课程都会详细讲解编译器设计,而且市面上也有很多优质资源可以帮助我们理解编译器的各个组成部分,包括解析器和解析树。然而,和大多数计算机科学内容一样,其中很多内容可能难以理解——尤其是在你不熟悉相关概念或术语的情况下。如果你想更深入地学习,以下是一些更适合初学者的资源,它们也能很好地解释解析树。
- 解析树,交互式 Python
- 语法、分析、树遍历,David Gries 教授和 Doug James 教授
- 让我们构建一个简单的解释器,第 7 部分,鲁斯兰·斯皮瓦克
- 解析指南:算法和术语,作者:Gabriele Tomassetti
- 第二讲:抽象句法和具体句法,阿内·兰塔
- 编译器和解释器,钟绍教授
- 编译器基础——解析器,詹姆斯·艾伦·法雷尔
文章来源:https://dev.to/vaidehijoshi/grammatically-rooting-oneself-with-parse-trees-16a