算法优化:一个实际案例
本文最初发表于steadbytes.com网站。
在一次面试中,我被要求分析
一段从运行中的生产软件中提取出来的 C 代码的复杂度(以及由此推断出的性能)。接下来,我将演示如何识别性能问题并实现解决方案。
这段代码最初是面试前测试的一部分,旨在讨论代码中存在的一些常见问题。我不会发布面试前测试题的解答(代码本身可能存在一些潜在问题),并且我已经修改了代码结构,使其无法被未来的应聘者搜索到。不过,其核心算法代表了一个有趣的“现实世界”优化问题,值得在本文中重点探讨。
原始read_file算法
顾名思义,该read_file函数将文件从磁盘读取到内存中,并将数据存储在
数组中,然后返回读取的总字节数:
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <stdlib.h>
#define BUFSIZE 4096
size_t read_file(int fd, char **data)
{
char buf[BUFSIZE];
size_t len = 0;
ssize_t read_len;
char *tmp;
/* chunked read from fd into data */
while ((read_len = read(fd, buf, BUFSIZE)) > 0)
{
tmp = malloc(len + read_len);
memcpy(tmp, *data, len);
memcpy(tmp + len, buf, read_len);
free(*data);
*data = tmp;
len += read_len;
}
return len;
}
算法复杂度
read_file由于循环 内部的操作,其空间和时间复杂度为O( n² ):memcpywhile
while ((read_len = read(fd, buf, BUFSIZE)) > 0)
{
/* allocate space for both existing and new data */
tmp = malloc(len + read_len);
/* copy existing data */
memcpy(tmp, *data, len);
/* copy new data */
memcpy(tmp + len, buf, read_len);
free(*data);
*data = tmp;
}
每次迭代都会将之前读取的所有数据复制到一个新数组中:
+-+
| |
+-+
| copy existing data
v
+-+ +-+
| | | |
+-+ +-+
| |
v | read new data
+--+ |
| | <-+
+--+
|
v
+--+ +-+
| | | |
+--+ +-+
| |
v |
+---+ |
| | <-+
+---+
|
v
+---+ +-+
| | | |
+---+ +-+
| |
v |
+----+ |
| | <--+
+----+
...
识别性能问题
计算算法的复杂度有助于大致了解其性能随输入规模的变化情况。然而,这与实际运行时间并不相同;例如,如果算法的输入规模很小,那么即使其复杂度为O(n² )也可能不是问题。在开始优化之前,应该始终对待优化的代码进行基准测试和/或性能分析。这有助于确定问题是否存在,以及提出的解决方案是否有效。
“真正的问题在于,程序员们在错误的地方和错误的时间花费了太多时间去关注效率;过早优化是编程中一切罪恶的根源(或者至少是大部分罪恶的根源)。”
——唐纳德·克努特,《计算机程序设计艺术》
main程序的入口点只是简单地从read_file标准输入读取数据,并打印读取的总字节数:
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <stdlib.h>
#define BUFSIZE 4096
size_t read_file(int fd, char **data);
int main(int argc, char *argv[])
{
char *data = NULL;
size_t len = read_file_improved(STDIN_FILENO, &data);
printf("%ld\n", len);
return 0;
}
使用随机生成的、大小逐渐增加的文本文件运行该程序,可以清楚地证明其复杂度为O(n 2 ):
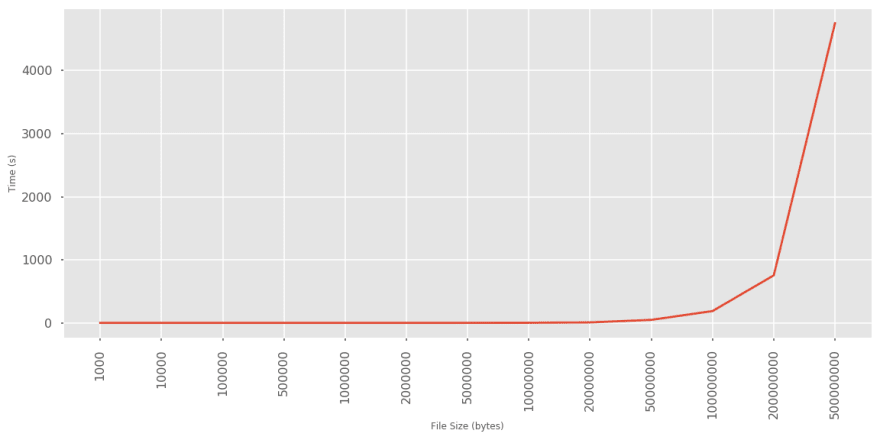
输入 0.5Gb 的文件竟然需要一个多小时才能完成!
改进算法
问题在于read_file数据需要重复复制——如果每个字节只复制
一次,时间复杂度将为O(n)。使用链表,可以按顺序存储从文件中读取的每个数据块的指针;在循环的每次迭代中创建一个新节点。循环结束后,只需遍历链表一次,即可将所有数据块复制到最终数组中。伪代码如下:data
typedef struct node_t
{
char *data; /* chunk of data read from file */
int len; /* number of bytes in chunk */
struct node_t *next; /* pointer to next node */
} node_t;
size_t read_file_improved(int fd, char **data)
{
char buf[BUFSIZE];
ssize_t read_len;
size_t len = 0;
/* build linked list containing chunks of data read from fd */
node_t *head = NULL;
node_t *prev = NULL;
while ((read_len = read(fd, buf, BUFSIZE)) > 0)
{
node_t *node = malloc(sizeof(node_t));
node->data = malloc(read_len);
memcpy(node->data, buf, read_len);
node->len = read_len;
node->next = NULL;
/* first chunk */
if (head == NULL)
{
head = node;
}
/* second chunk onwards */
if (prev != NULL)
{
prev->next = node;
}
prev = node;
len += read_len;
}
/* copy each chunk into data once only */
*data = malloc(len);
char *p = *data;
node_t *cur = head;
while (cur != NULL)
{
memcpy(p, cur->data, cur->len);
p += cur->len;
cur = cur->next;
}
return len;
}
算法复杂度
构建链表(假设node_t结构体的开销恒定)的时间复杂度为O(n);文件中的每个字节都会被读取到一个数组中,然后不再被修改:
file reads
+------+------+
| | |
V V V
+-+ +-+ +-+
| | -> | | -> | | ...
+-+ +-+ +-+
- 方框之间的箭头表示链表节点指针。
将链表中的数据块复制到目标位置的最后一步data也是O(n);遍历链表中的指针是O(1),并且每个数据块中的每个字节都会被复制一次。
合起来,O(2n) ~= O(n)
性能比较
为了对每种实现进行基准测试,main入口点经过调整,可以接受一个可选--slow参数,用于在默认使用改进算法和使用原始算法之间切换:
int main(int argc, char *argv[])
{
size_t len;
char *data = NULL;
/* default to improved implementation*/
if (argc == 1)
{
len = read_file_improved(STDIN_FILENO, &data);
}
/* optionally specify original implementation for comparison purposes */
else if (argc == 2 && !strcmp(argv[1], "--slow"))
{
len = read_file(STDIN_FILENO, &data);
}
else
{
fprintf(stderr, "usage: read_file [--slow]\nReads from standard input.");
return 1;
}
/* do some work with data */
printf("%ld\n", len);
return 0;
}
使用相同的基准测试方法对随机生成的文本文件进行测试,可以得到
非常清晰的结果:
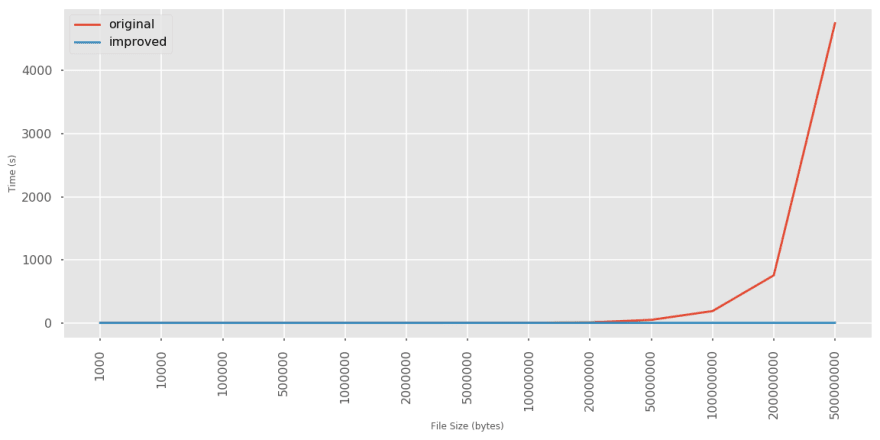
结论
理解算法复杂度是实现高性能程序的关键。然而,为了避免过早优化,还应该结合性能基准测试。本文将演示如何:
- 找出性能问题
- 确定算法的复杂度
- 重新设计算法以提高性能
- 证明优化的有效性
完整的代码,包括基准测试脚本和分析,可以在GitHub上找到,链接在此。
文章来源:https://dev.to/steadbytes/algorithm-optimization-a-real-example-4988