使用 Pandas 进行时间序列分析
我们将使用 Python 3、pandas 和 Matplotlib 分析股票数据。为了更好地理解本文,您应该熟悉 pandas 的基础知识以及名为 Matplotlib 的绘图库。
时间序列数据
时间序列数据是一系列按时间顺序排列的数据点,企业利用这些数据来分析历史数据并进行未来预测。这些数据点是在特定时间以等间隔进行的一系列观测值,通常包含日期时间索引和相应的值。日常生活中常见的时间序列数据示例包括:
- 测量天气温度
- 统计每月出租车乘车次数
- 预测公司第二天的股票价格
时间序列数据的变化
- 趋势波动:在较长一段时间内,以相当可预测的模式向上或向下移动。
- 季节性变化:有规律且周期性;在特定时期内重复出现,例如一天、一周、一个月、一个季节等。
- 周期性波动:与商业或经济的“繁荣-萧条”周期相对应,或以其他某种形式呈现周期性变化
- 随机变异:不稳定的或残余的;不属于以上三种分类中的任何一种。
以下是四种时间序列数据可视化形式:

导入股票数据和必要的 Python 库
为了演示如何使用 pandas 进行股票分析,我们将使用 2013 年至 2018 年的亚马逊股票价格数据。数据来自 Quandl,该公司提供 Python API,用于获取各种市场数据。本文所用数据的 CSV 文件可从文章的存储库中下载。
打开你选择的编辑器,输入以下代码以导入与本文对应的库和数据。
本文的示例代码可以在Github 上的 Kite Blog 代码库 中找到。
# Importing required modules
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Settings for pretty nice plots
plt.style.use('fivethirtyeight')
plt.show()
# Reading in the data
data = pd.read_csv('amazon_stock.csv')
亚马逊股票价格初探
我们来看一下数据集的前几列:
# Inspecting the data
data.head()
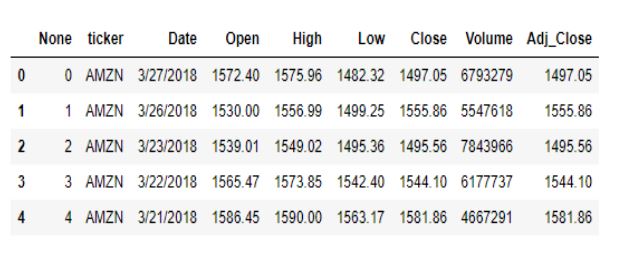
让我们删除前两列,因为它们对数据集没有任何价值。
data.drop(columns=['None', 'ticker'], inplace=True)
data.head()

现在让我们来看一下各个组件的数据类型。
data.info()
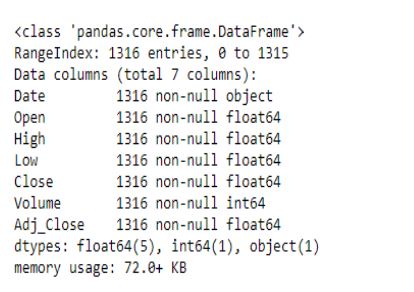
看起来 Date 列被当作字符串而不是日期处理了。为了解决这个问题,我们将使用 pandas 的转换to_datetime()功能,将参数转换为日期。
# Convert string to datetime64
data['Date'] = data['Date'].apply(pd.to_datetime)
data.info()
最后,我们要确保“日期”列是索引列。
data.set_index('Date', inplace=True)
data.head()
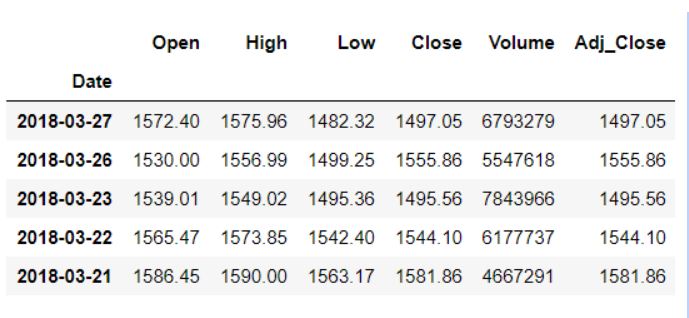
现在我们的数据已经转换成了所需的格式,让我们来看看它的列,以便进行进一步的分析。
- “开盘价”和“收盘价”列分别表示股票在特定日期的开盘价和收盘价。
- “最高价”和“最低价”列分别显示股票在特定日期的最高价和最低价。
- “成交量”一栏显示的是特定日期股票的总交易量。
该Adj_Close列显示的是调整后的收盘价,即股票在任意交易日的收盘价,已根据次日开盘前发生的任何分红和/或公司行为进行了调整。调整后的收盘价通常用于分析历史收益。
data['Adj_Close'].plot(figsize=(16,8),title='Adjusted Closing Price')
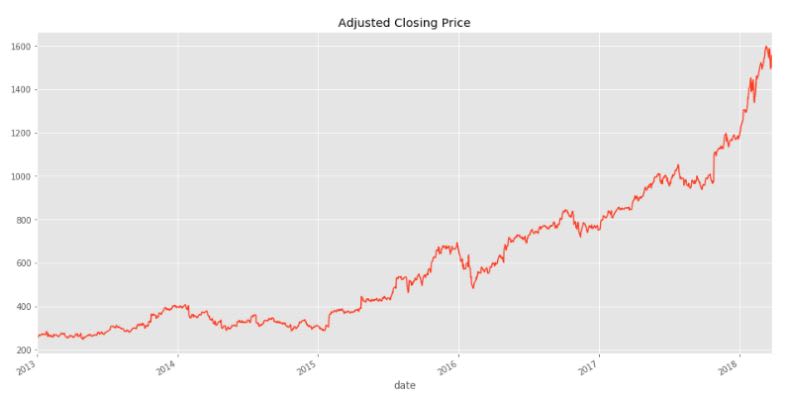
有趣的是,亚马逊的股价在2013年至2018年期间似乎呈现相对稳定的增长趋势。接下来,我们将使用pandas库来分析和处理这些数据,以获得一些见解。
用于时间序列分析的 Pandas
由于 pandas 最初是为金融建模而开发的,因此它包含了一套全面的工具,用于处理日期、时间和时间索引数据。接下来,我们来看看 pandas 中用于处理时间序列数据的主要数据结构。
操纵datetime
Python 处理日期和时间的基本工具位于内置datetime模块 pandas 中。在 pandas 中,单个时间点表示为一个日期时间对象 (datetime),pandas.Timestamp我们可以使用 ` datetime` 函数从各种日期/时间格式的字符串datetime()创建日期时间对象。日期时间对象 (datetime) 与日期时间对象 (datetime) 可以互换使用。datetimepandas.Timestamp
from datetime import datetime
my_year = 2019
my_month = 4
my_day = 21
my_hour = 10
my_minute = 5
my_second = 30
现在我们可以创建一个datetime对象,并根据上述属性在 pandas 中自由使用它。
test_date = datetime(my_year, my_month, my_day)
test_date
# datetime.datetime(2019, 4, 21, 0, 0)
为了分析我们的特定数据,我们只选择了日、月和年,但如有必要,我们也可以添加更多详细信息,如小时、分钟和秒。
test_date = datetime(my_year, my_month, my_day, my_hour, my_minute, my_second)
print('The day is : ', test_date.day)
print('The hour is : ', test_date.hour)
print('The month is : ', test_date.month)
# Output
The day is : 21
The hour is : 10
The month is : 4
对于我们的股票价格数据集,索引列的类型是DatetimeIndex。我们可以使用 pandas 来获取数据中的最小值和最大值。
print(data.index.max())
print(data.index.min())
# Output
2018-03-27 00:00:00
2013-01-02 00:00:00
我们还可以按如下方式计算最新日期位置和最早日期索引位置:
# Earliest date index location
data.index.argmin()
#Output
1315
# Latest date location
data.index.argmax()
#Output
0
时间重采样
对于金融机构而言,逐日分析股票价格数据意义不大,他们更关注的是把握市场趋势。为了简化这一过程,我们采用一种称为时间重采样的技术,将数据汇总到特定的时间段内,例如按月或按季度。这样,机构就能概览股票价格走势,并根据这些趋势做出决策。
pandas 库提供了一个resample()函数,可以对这类时间序列数据进行重采样。pandas 中的 resample 方法与它自身的方法类似groupby,本质上都是根据特定的时间跨度进行分组。该resample()函数如下所示:
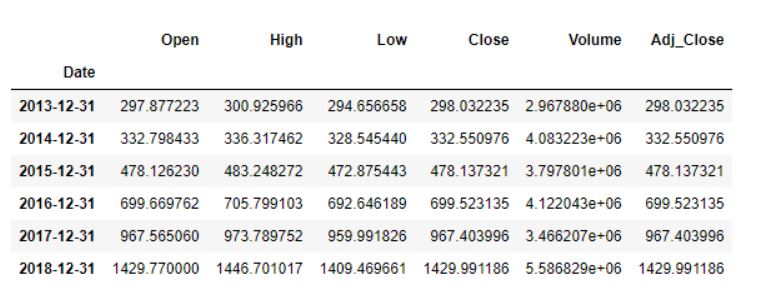
data.resample(rule = 'A').mean()
总结起来:
data.resample()用于对股票数据进行重采样。- “A”代表年末频率,表示我们要对数据进行重新采样的偏移值。
mean()这表明我们想要的是这段时间内的平均股价。
输出结果如下所示,显示的是每年12月31日的平均股票数据。
以下是偏移量值的完整列表。该列表也可在 pandas 文档中找到。

时间重采样的偏移别名
我们还可以使用时间抽样来绘制特定列的图表。
data['Adj_Close'].resample('A').mean().plot(kind='bar',figsize = (10,4))
plt.title('Yearly Mean Adj Close Price for Amazon')
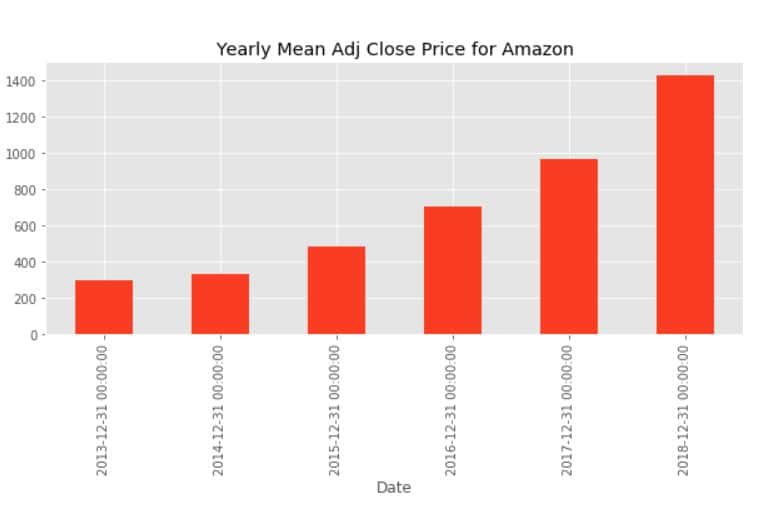
上图所示的柱状图对应于我们数据集中每年亚马逊年末的平均调整后收盘价。
同样,每年的每月最高开盘价如下所示。

亚马逊每月最高开盘价
时间转移
有时,我们需要将数据向前或向后移动。这种移动是沿着时间索引,按所需的时间频率增量数进行的。
继续进行时间偏移,并在 Kite Github 仓库中查看代码。
Parul Pandey是 H2O.ai 的数据科学布道者,也是 Kite Blog 的作者。
文章来源:https://dev.to/kite/time-series-analysis-with-pandas-3472