Brain.js 神经网络入门
由 Mux 赞助的 DEV 全球展示挑战赛:展示你的项目!
什么是神经网络
神经网络是一种极其有用的计算结构,它使计算机能够处理复杂的输入并学习如何对其进行分类。神经网络的功能源于其结构,而这种结构又基于大脑中的模式。
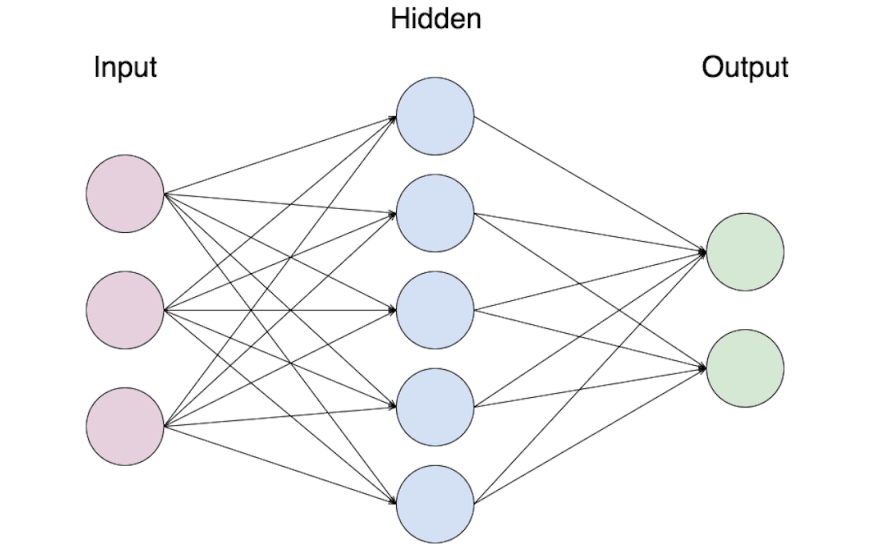
请注意,该网络分为三个不同的层。当神经网络运行时,它会从左到右依次激活各层,从输入层到输出层。神经网络也可以有多个隐藏层,但我们稍后再讨论。
上图中的每个圆圈代表一个神经元。每个神经元负责测量一个特定的变量,神经元所在的层级越高,该变量所包含的信息就越多。输入神经元可能测量单个像素的亮度,中间的神经元可能描述图像中的各个元素,而输出神经元则描述整幅图像。该值是一个介于特定范围(例如 0 到 1 之间)的数值,称为神经元的激活值。神经元还有一个称为偏置的值,它会使神经元的默认值偏离 0.5。
每一层中的每个神经元都与下一层中的每个神经元相连。每个连接都有一个权重,该值表示两个神经元之间的关系。较高的正权重意味着第一个神经元会使第二个神经元更容易被激活,而较高的负权重则意味着第一个神经元会阻止第二个神经元被激活。权重为 0 则意味着第一个神经元对第二个神经元完全没有影响。
当输入数据进入神经网络时,它会在第一层生成一组激活值。该层中的每个连接会依次“激活”。当一个连接激活时,它会将左侧神经元的激活值乘以该连接的权重,然后将结果与偏置项一起加到右侧神经元的累计总和中。在此过程结束时,左侧层中的每个神经元都对右侧层中的每个神经元做出了贡献。
由于结果值可以位于数轴上的任何位置,而激活值必须介于 0 和 1 之间,因此我们需要使用一个函数将结果转换为合适的范围。有很多函数可以用于此目的,例如 Sigmoid 函数。一旦为该层中的每个神经元生成了激活值,该过程就会重复进行,直到到达输出层。
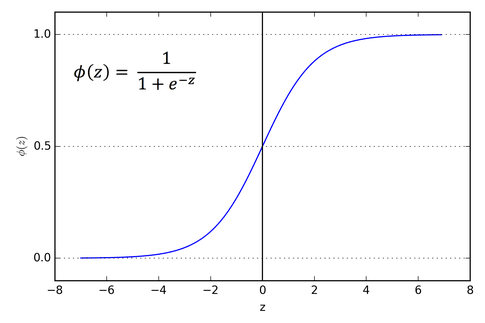
例如,在下面的例子中,第一行的三个节点共同影响下一行的一个节点。最上面的节点贡献 4.0 * 0.5 = 2.0,中间的节点贡献 0.5,最下面的节点贡献 -1,三者之和为 1.5。受影响的节点还有一个 -2 的偏差,因此总和为 -0.5。将此值代入 Sigmoid 函数,得到的激活值为 0.378。

好的,我们有一些数学方法可以让我们重新排列一些数字,但任何函数都可以做到这一点。为什么我们需要神经元、连接和层这些复杂的概念呢?
学习
神经网络中存在许多未知因素,网络中的每个神经元都有一个偏置,神经元之间的每个连接都有一个权重。所有这些值都可以进行调整和修改,从而产生具有不同行为的神经网络。当然,大多数可能的组合都会给出完全无用的结果。我们如何从无限多的组合中筛选出少数几个可用的组合呢?
首先,我们需要定义一种方法来衡量神经网络的任何给定配置的性能。这可以通过创建一个成本函数来实现,成本函数通常是预期结果与实际结果之差的平方和。当成本函数值很高时,网络的性能很差。但当成本函数值接近于0时,网络的性能非常好。仅仅知道网络处理单个样本的性能并没有太大用处,因此需要用到大型数据集。一组权重和偏置的有效性是通过在神经网络中运行数百甚至数千个样本来确定的。

如果我们绘制出参数所有可能取值对应的成本函数图像,就会得到一个类似于(但复杂得多)上图的图形。由于这是成本函数,图上的最低点代表了最精确的参数组合。因此,我们可以使用最速下降法找到函数的局部最小值。最速下降法需要找到图中相邻区域的最高斜率,然后沿着该斜率线向下移动。这涉及到大量的微积分运算,我没有时间在这里一一赘述,而且计算速度非常慢。
利用反向传播加速学习
反向传播提供了一种更快速的近似最速下降法的方法。其核心思想是:将一个样本输入神经网络,找出结果与期望值之间的偏差,然后找到能够使结果接近期望值的最小调整量。
这种方法之所以有效,是因为神经网络具有广泛的分支结构。由于神经元会经过许多不同的路径,而每条路径都具有不同的权重,因此可以找到对你关心的值影响比其他值大一个数量级的调整值。遵循这一过程,你会得到一系列需要对现有权重和偏差值进行的更改。直接应用这些更改会导致数据集过拟合,因此在进行任何更改之前,你需要获得一个良好的平均值。你应该打乱数据集,得到随机的样本组合,并为每个样本生成一系列更改列表。将几百个这样的列表取平均值后,你就可以对网络进行更改了。虽然由此产生的每次单独的调整都不会直接使网络达到最速下降,但平均值最终会将成本函数拉近到局部最小值。
理论就到此为止吧!
Brain是一个专为轻松实现高级神经网络而设计的 JavaScript 库。Brain 几乎可以处理所有设置,让您只需专注于高级决策。
缩放函数:设置用于确定神经元激活值的函数。
隐藏层数:输入层和输出层之间的额外层数。对于任何项目,几乎没有理由使用超过两层。增加层数会大幅增加计算时间。
迭代次数:网络在停止前遍历训练数据的次数。
学习率:一个全局标量,用于控制可以调整的值的大小。太低,需要很长时间才能收敛到答案。太高,可能会错过局部最小值。
const network = new brain.NeuralNetwork({
activation: ‘sigmoid’, //Sets the function for activation
hiddenLayers: [2], //Sets the number of hidden layers
iterations: 20000, //The number of runs before the neural net stops training
learningRate: 0.4 //The multiplier for the backpropagation changes
})
上述参数将作为对象传递给 NeuralNetwork 类。然后可以使用 `.train` 方法训练网络。这需要预先准备好的训练数据。样本数据应结构化为包含输入值和输出值的对象数组。输入值和输出值应为数字数组,分别对应于网络第一层和最后一层神经元的激活值。输入数组和输出数组中的元素数量必须保持一致(内部而言,它们不必相等),因为这决定了网络前端和后端节点的数量。
let trainingSample1 = {
input: [ 5.3, 6 , 1 , -4 ]
output: [ 0 , 1 ]
}
let trainingSample2 = {
input: [ 1 , -14 , 0.2 , 4.4 ]
output: [ 1 , 1 ]
}
trainingData.push( trainingSample1 )
trainingData.push( trainingSample2 )
network.train(trainingData)
现在,网络已经尽力根据您选择的设置和样本进行自我训练。您可以使用 `.run` 命令来检查给定样本的输出。瞧,您的网络现在能够根据任何给定的输入进行近似计算了。如果您没有读完这 1000 字的解释,我真会觉得这简直像魔法一样。
let sample = [20, -3, -5, 13]
let result = network.run(sample)