Amazon Bedrock:面向开发人员和 DevOps 工程师的实用指南
曾几何时,构建人工智能应用需要深厚的传统技术经验和一定的机器学习专业知识。虽然这曾是常态,但开发者必须根据自身需求配置模型、提供GPU并手动优化性能,这需要耗费大量精力和成本。
尽管这种方法看似困难,但 AWS 团队开发了 Amazon Bedrock,这是一款允许开发人员使用其内置基础模型,通过 API 或 AWS 管理控制台轻松创建 AI 应用程序的工具。Amazon Bedrock 使开发人员能够构建生成式 AI 应用程序,而无需直接管理底层技术栈。

本文将全面介绍 Amazon Bedrock,包括使用 Amazon Bedrock 的先决条件、入门指南、最佳实践,以及其核心概念。此外,您还将看到一些如何使用 AWS Bedrock API 的代码示例。因此,本文将作为一份 面向 希望使用 Bedrock 构建生成式 AI 应用的用户的Amazon 指南。
请大家支持Microtica 😅 🙏
在继续之前,如果您能加入我们的社区,支持我们在Microtica的工作,我将不胜感激!⭐️

什么是亚马逊基岩?
Amazon Bedrock 是一项服务,可帮助 DevOps 工程师和团队构建生成式 AI 应用。Amazon Bedrock 无需手动构建或微调模型,而是利用 AI 基础设施提供商提供的基础模型,为开发人员提供现成的 API,方便他们轻松使用。这种方法消除了构建生成式应用和使用底层技术栈所带来的复杂性。
亚马逊基岩的好处
在深入了解 Amazon Bedrock 之前,我想先分享一下 Amazon Bedrock 的一些优势,并举例说明这些优势如何对您的开发工作流程产生积极影响。
- 更快的开发速度:与手动操作模型并不断进行微调相比,AWS 允许您使用单一 API。这种方式让您无需过多关注其他方面,节省了大量时间,因为它比直接操作模型更省力。
- 例如:我的同事利用亚马逊 Bedrock 的文本生成模型开发了一个 AI 助手,无需直接处理任何机器学习模型,这节省了他不少时间。他发现这种方法速度更快,因为他只需几天时间就能通过 API 调用添加 AI 功能,而无需花费数月甚至数周的时间。
- 可扩展性:Amazon Bedrock 构建于 AWS 云基础设施之上,并使用了来自多家公司的模型,包括 AI21 Labs、Anthropic、Cohere、DeepSeek、Luma、Meta、Mistral AI 和 Stability AI。这使得团队能够轻松扩展其应用程序,并且在高负载情况下,Bedrock 也能确保卓越的应用程序性能,无需人工干预。
- 例如:使用 Amazon Bedrock 进行产品推荐的电子商务服务可以在购物旺季轻松扩展资源,而不会影响性能或出现停机时间。
- 与 AWS 生态系统集成:由于 Amazon Bedrock 是 AWS 产品,因此它可以与 Amazon SageMaker、Lambda 和 S3 无缝集成,用于构建、部署和管理应用程序。
- 例如:一家使用 Amazon Bedrock 进行欺诈检测的银行可以创建自动化工作流程。例如,AWS Lambda 可以识别可疑交易,将报告保存到 S3,并使用 SageMaker 来检查模式。
- 成本效益: Amazon Bedrock 提供灵活的定价方案,您只需为实际使用的资源付费。您无需花费大量资金购买昂贵的服务器和模型,而是可以选择 Bedrock 的任何一种模型,既能帮助您节省成本,又能获得强大的 AI 功能。您可以访问此页面查看 Amazon Bedrock 的定价模型。
- 例如:我的一位同事使用 Amazon Bedrock 自动生成博客文章,并且只为她使用的 API 请求付费,从而节省了监控和微调 AI 模型的费用。
Amazon Bedrock 入门指南🚀
现在,是时候开始动手实践了。在本节中,我们将探讨实际操作步骤以及开始之前需要准备的事项。尽管 Amazon Bedrock 可以用于完成许多任务,但本文仅专注于如何使用 AWS 管理控制台轻松构建生成式 AI 应用程序。
使用亚马逊基岩版的前提条件
在开始使用 Amazon Bedrock 之前,您需要准备以下物品:
- Python基础知识。
- AWS 账户:这是最基本的:要开始使用,您需要 创建一个 AWS 账户。
- AWS 管理控制台:如果您不想编写代码,则需要使用控制台与模型进行交互。或者,您也可以使用:
- AWS CLI:您可以使用 CLI 通过 API 创建 AWS CLI 配置文件。有关如何使用此选项的说明,请参阅此文档。此选项需要一些基本的 Python 知识。
- IAM 权限:您还需要分配 Bedrock 所需的 IAM 角色。

本文将使用 AWS 管理控制台进行操作。您也可以使用 CLI 进行一些实际操作。
人工智能/机器学习基础概念
尽管 Amazon Bedrock 有助于简化构建 AI 应用程序的复杂性,但对 AI 和 ML 的基本了解仍然很有帮助,因为即使在使用 Amazon Bedrock 时,您也可能会遇到一些问题,例如:
- 基础模型 (FM):这些是 Amazon Bedrock 为生成式应用程序操作提供的预构建 AI 模型。您可能会想知道 AWS 是否拥有所有模型,但实际上其中一些模型来自不同的公司。
- 提示工程: 这是创建和改进输入提示的过程,旨在帮助人工智能模型生成准确且优质的响应。良好的提示工程可以提升模型的理解能力,并确保其输出与预期一致。
- 模型微调:借助 Amazon Bedrock,您可以根据自身需求对模型进行微调。您可以随时配置模型以满足您的需求;此方法与手动配置方法有所不同。
亚马逊基岩的核心概念
现在,让我们来看看亚马逊基岩版的一些关键概念——通过快速了解这些概念,您将更深入地了解亚马逊基岩版的工作原理以及如何充分利用它。
理解基础模型
让我们来看看亚马逊基岩 (Amazon Bedrock) 使用的一些基础模型,以及在使用它们之前需要考虑的事项。
要查找您可以使用的模型列表、它们的功能以及在您所在地区的可用性, 请参阅此指南。该指南将详细介绍所有模型及其生成的输出类型,例如图像、文本或代码。
以下是您在使用任何模型之前应该考虑的一些事项:
- 使用场景:您应该了解该模型是否符合您的应用程序需求。例如,如果您正在构建一个生成文本回复的聊天机器人,则需要使用支持文本输出的模型。
- 性能与成本:现在,就到了“质量胜于数量”这句话真正发挥作用的时候了。你需要考虑两件事:性能和成本。有些型号速度很快,但通常价格昂贵。如果你想要一款符合预算的型号,你可能需要在性能和价格之间找到一个平衡点。
- 自定义:Amazon Bedrock 允许您针对某些用途调整模型。根据您的需求,您可能需要一个可以自定义以适应您项目的模型。
Amazon Bedrock API
现在,让我们来探索 Amazon Bedrock 的 API 和 SDK,并学习如何使用它们。首先,我们将了解 API,并学习如何使用基础模型。
概述
除了与服务交互之外,Amazon Bedrock API 还允许您执行以下操作:
- 使用基础模型生成文本、创建图像和生成代码
- 通过更改设置来调整模型的行为。
- 获取有关该模型的信息,包括其 ARN 和 ID。
Amazon Bedrock API 使用 AWS 的标准身份验证和授权方法,这需要 IAM 角色和权限以确保安全。
身份验证和访问控制
要使用 Bedrock API,您需要安装 最新版本的 AWS CLI 并使用 AWS IAM 凭证登录。请确保您的 IAM 用户或角色也拥有所需的权限。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "MarketplaceBedrock",
"Effect": "Allow",
"Action": [
"aws-marketplace:ViewSubscriptions",
"aws-marketplace:Unsubscribe",
"aws-marketplace:Subscribe"
],
"Resource": "*"
}
]
}
此策略允许您使用 API 运行模型。要了解如何使用 Amazon Bedrock 的 API,您可以参考并阅读以下指南:
- Amazon Bedrock API 参考:在本文档中,您将找到您可能会用到的服务端点。
- Amazon Bedrock API 入门:本文档将引导您了解有关 Amazon Bedrock API 的所有信息——从安装要求到使用方法;这是一份更详细的设置指南。
AWS SDK 集成
AWS 提供 SDK,可与您喜爱的编程语言(例如 Python、Java、Go、JavaScript、Rust 等)集成。现在,让我们来看一些它们如何与不同语言配合使用的示例。
- Python (Boto3):
import logging
import json
import boto3
from botocore.exceptions import ClientError
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def list_foundation_models(bedrock_client):
try:
response = bedrock_client.list_foundation_models()
models = response["modelSummaries"]
logger.info("Got %s foundation models.", len(models))
return models
except ClientError:
logger.error("Couldn't list foundation models.")
raise
def main():
bedrock_client = boto3.client(service_name="bedrock")
fm_models = list_foundation_models(bedrock_client)
for model in fm_models:
print(f"Model: {model['modelName']}")
print(json.dumps(model, indent=2))
print("---------------------------\n")
logger.info("Done.")
if __name__ == "__main__":
main()
这是一个使用 Python (Boto3) 列出可用 Amazon Bedrock 模型的清晰示例。要了解有关 Python SDK 工作原理的更多信息, 请阅读此指南。
- JavaScript 示例(AWS SDK for JavaScript v3):
import { fileURLToPath } from "node:url";
import {
BedrockClient,
ListFoundationModelsCommand,
} from "@aws-sdk/client-bedrock";
const REGION = "us-east-1";
const client = new BedrockClient({ region: REGION });
export const main = async () => {
const command = new ListFoundationModelsCommand({});
const response = await client.send(command);
const models = response.modelSummaries;
console.log("Listing the available Bedrock foundation models:");
for (const model of models) {
console.log("=".repeat(42));
console.log(` Model: ${model.modelId}`);
console.log("-".repeat(42));
console.log(` Name: ${model.modelName}`);
console.log(` Provider: ${model.providerName}`);
console.log(` Model ARN: ${model.modelArn}`);
console.log(` Input modalities: ${model.inputModalities}`);
console.log(` Output modalities: ${model.outputModalities}`);
console.log(` Supported customizations: ${model.customizationsSupported}`);
console.log(` Supported inference types: ${model.inferenceTypesSupported}`);
console.log(` Lifecycle status: ${model.modelLifecycle.status}`);
console.log(`${"=".repeat(42)}\n`);
}
const active = models.filter(
(m) => m.modelLifecycle.status === "ACTIVE",
).length;
const legacy = models.filter(
(m) => m.modelLifecycle.status === "LEGACY",
).length;
console.log(
`There are ${active} active and ${legacy} legacy foundation models in ${REGION}.`,
);
return response;
};
if (process.argv[1] === fileURLToPath(import.meta.url)) {
await main();
}
上面的代码片段还显示了可用的 Bedrock 地基模型列表。要了解有关如何使用 JavaScript SDK 的更多信息, 请阅读此指南。
这里有一些代码示例,展示了如何将 Bedrock SDK 集成到您喜欢的编程语言中。您可以在 本指南中找到它们。
了解 Amazon Bedrock API 响应
现在,让我们来看看 Amazon Bedrock 为模型预测提供的主要 API 操作:
- InvokeModel – 发送一个提示并获取响应。
- Converse – 允许通过包含先前的消息来进行对话。
此外,Amazon Bedrock 支持使用 InvokeModelWithResponseStream 和 进行 流式响应ConverseStream。
InvokeModel 要查看使用`and` 提交单个提示时会收到哪些类型的响应 Converse,请查看以下指南:
- Converse API:本指南展示了如何使用 Converse API 来操作 Amazon Bedrock。它还包括如何使用 Amazon Bedrock 运行时端点
Converse发出请求,以及使用 `response` 或 `response.json` 两种方式将获得的响应示例ConverseStream。 - InvokeModel:本指南解释了如何
InvokeModel在 Amazon Bedrock 中使用此操作。它还涵盖了如何向基础模型发送请求、设置参数以获得最佳结果以及如何管理响应。
使用 Amazon Bedrock 构建对话式 AI 应用程序
现在,让我们开始使用 AWS 管理控制台在 Amazon Bedrock 中构建我们的第一个应用程序。在这个项目中,我们将创建一个仅处理文本的对话式 AI 助手。
步骤 1:在 AWS 管理控制台中开始使用 Amazon Bedrock
首先,通过 AWS 主登录 URL 登录 AWS 管理控制台。登录后,您将被重定向到控制面板。在控制面板中,选择 Amazon Bedrock 选项(在 AWS 搜索栏中搜索“Bedrock”)。
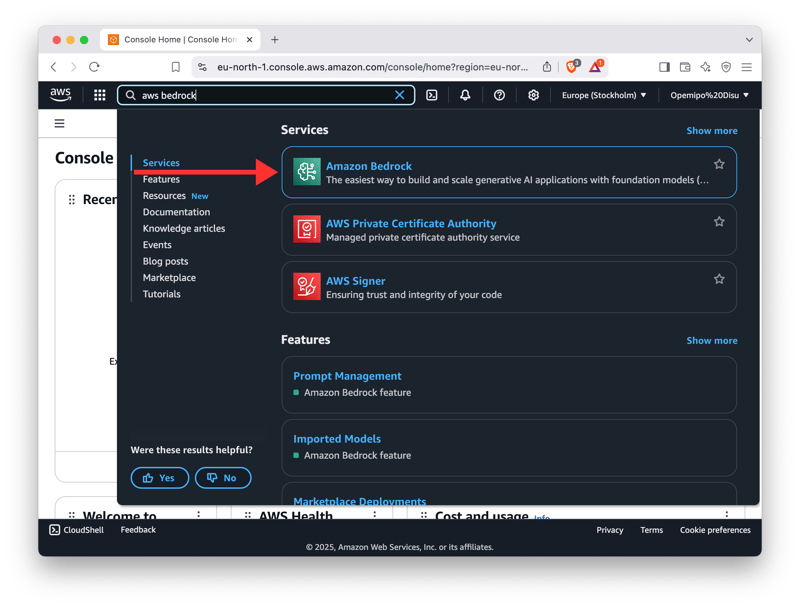
选择 Amazon Bedrock 后,前往 “模型访问”选项 卡,并通过请求访问权限来确保您可以访问任何 Amazon Titan 文本生成模型。
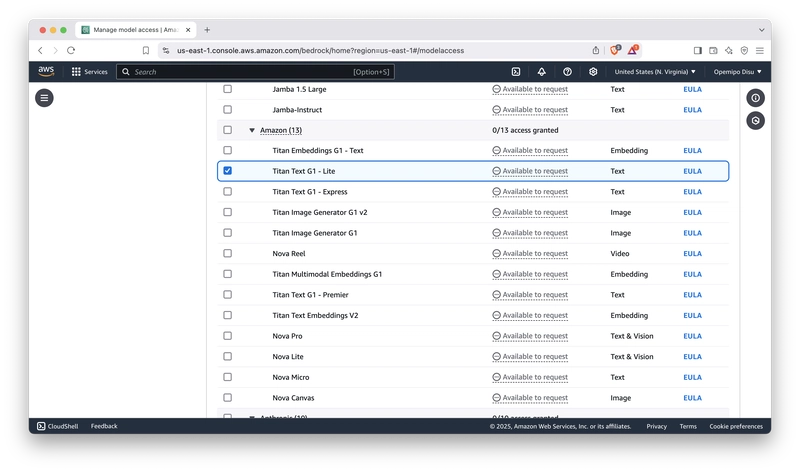
选择您想要使用的模型后,点击“ 下一步” 按钮。之后,您将被重定向到一个标签页,您需要在该标签页提交访问模型的请求。
步骤 2:使用 Amazon Titan 构建聊天机器人
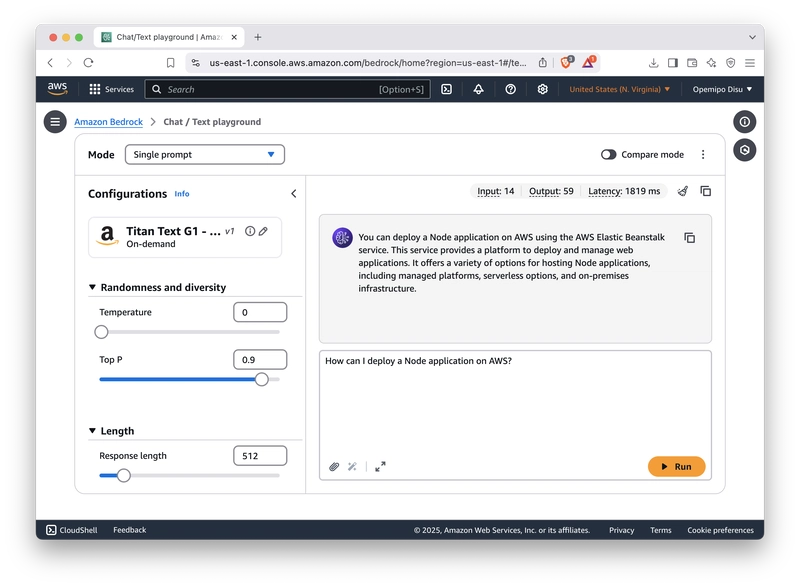
前往 侧边导航栏的 “游乐场”部分,然后选择“聊天/文本” 部分。在游乐场中输入提示信息。点击“ 运行” 按钮,即可使用 Titan 的文本模型生成回复。
步骤 3:使用 AWS Lambda 部署聊天机器人
现在,让我们使用AWS Lambda将聊天机器人部署 为无服务器应用程序!首先,我们需要创建一个 AWS Lambda 函数。以下是创建 AWS Lambda 函数的步骤:
- 导航至 AWS Lambda 并创建一个函数。
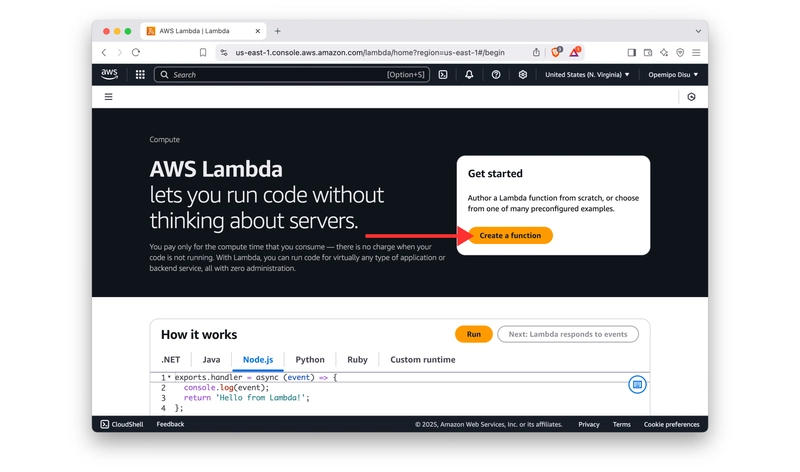
- 选择 “从零开始创建”选项 卡并进行部署配置。请注意,运行时环境应为 Python 3.10。
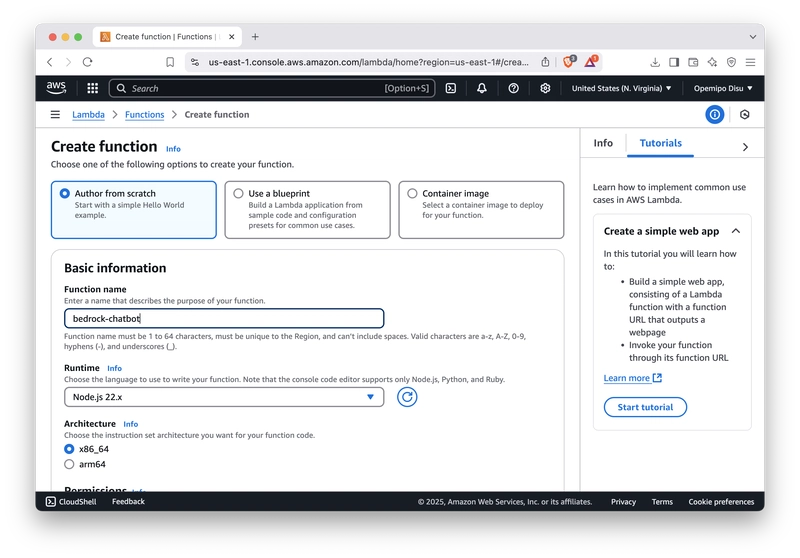
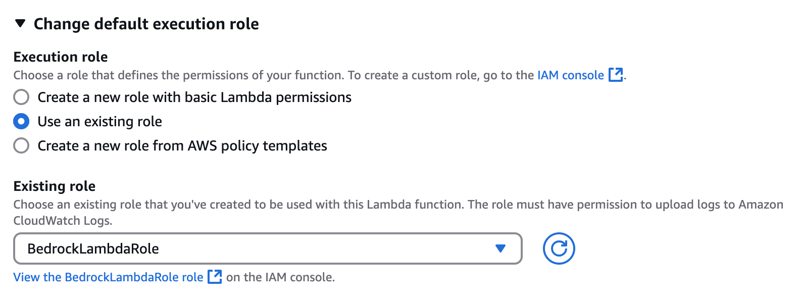
- 创建一个拥有 Bedrock 和 CloudWatch 完全访问权限的角色。
- 创建函数!🚀
在 Lambda 函数中添加一些代码,然后点击 “部署” 按钮。
import json
import boto3
bedrock = boto3.client('bedrock-runtime')
def lambda_handler(event, context):
user_input = event['queryStringParameters']['message']
response = bedrock.invoke_model(
body=json.dumps({
"prompt": user_input,
"maxTokens": 200
}),
modelId="amazon.titan-text-lite-v1"
)
model_output = json.loads(response['body'].read().decode('utf-8'))
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"response": model_output["completions"][0]["data"]["text"]})
}
步骤 4:使用 API 网关部署 API
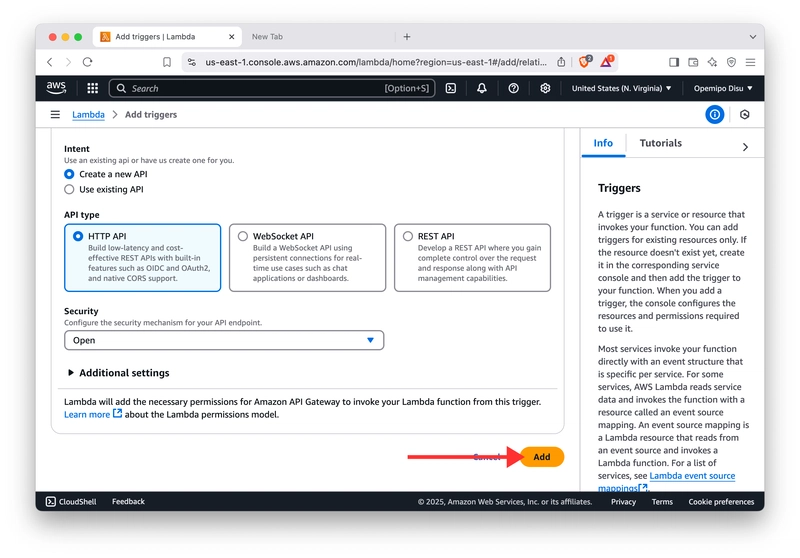
- 在“功能概览”下 ,单击 “添加触发器” 按钮,然后选择 API 网关 选项。
- 创建HTTP API并配置API端点的安全方法。
-
部署 API!🤘
-
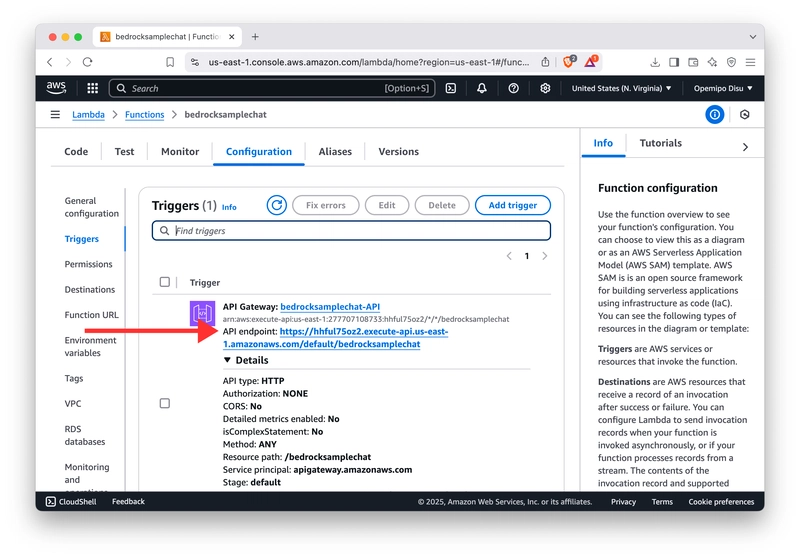
记下你的 Invoke URL ,即可与聊天机器人互动!🚀
-
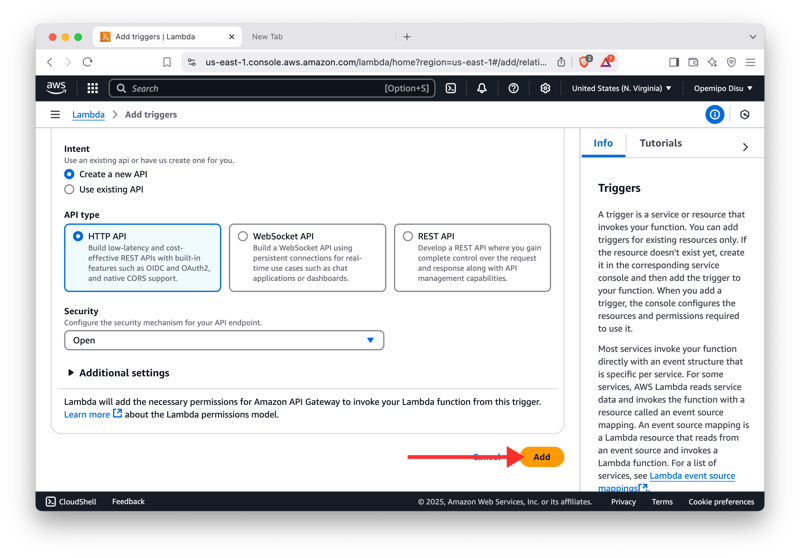
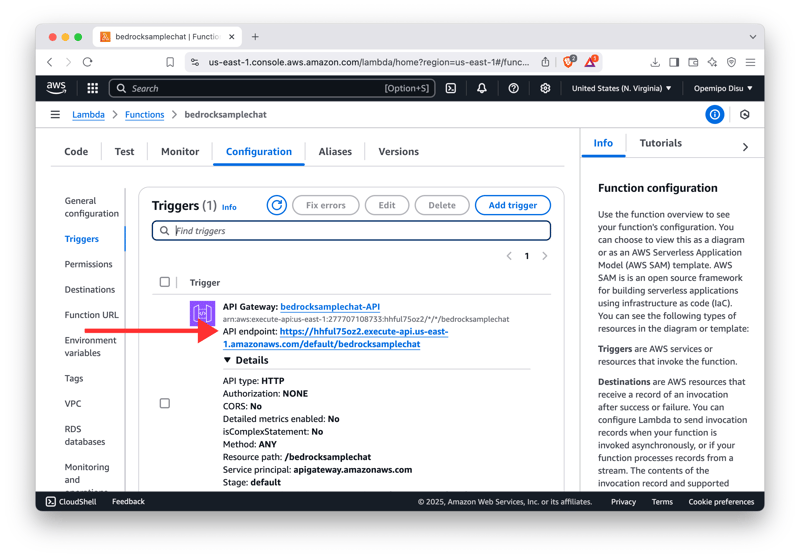
最后,您就可以与 API 的端点进行交互并使用它进行构建了。😎
使用 Amazon Bedrock 和 Anthropic Bedrock 构建代码生成工具
现在,让我们来构建一些更有趣、更具技术性的东西。在本节中,我们将使用 Amazon Bedrock 和 Anthropic Claude 2.0 模型(一个以生成代码作为响应的模型)构建一个代码生成工具。别担心,我们仍然会使用 AWS 管理控制台,但本用例需要您具备基本的 Python 知识。
步骤 1:导航至基岩版并选择 Anthropico Claude 2.0 模型
就像我们在聊天机器人用例中所做的那样,在 AWS 管理控制台中访问 Amazon Bedrock。转到 “Playground”部分 下的 “聊天/文本”部分 。
在“选择模型”下拉菜单中 ,选择 Anthropic Claude 2.0 模型。完成后,您现在可以在聊天中输入与代码相关的提示。
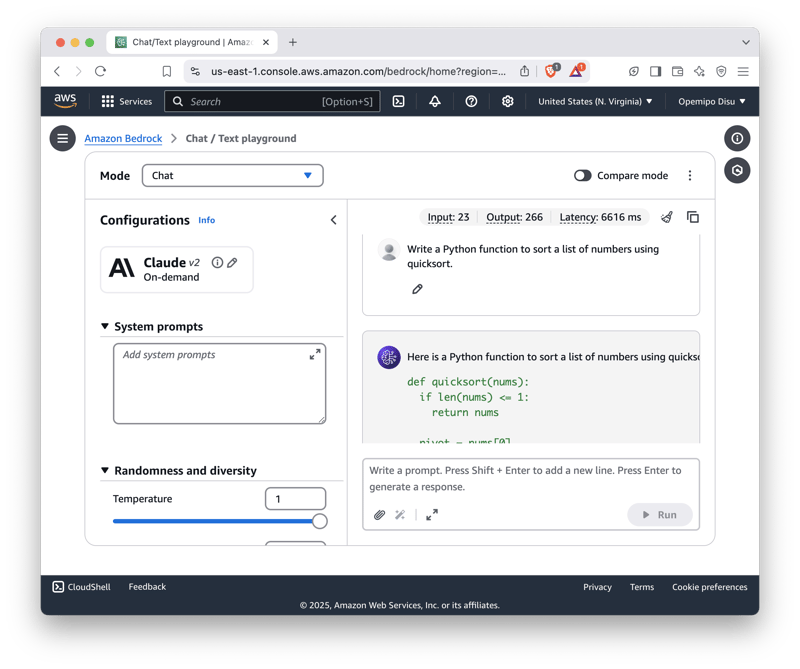
这是一个非常棒的模型,因为它不仅生成代码,还会解释代码的功能和工作原理。它是一款超级快速高效的模型!
使用 AWS Lambda 部署代码生成用例
就像我们在第一个用例中所做的那样,我们也将使用 AWS Lambda 部署代码生成。
- 创建一个新的 Lambda 函数
向 Lambda 函数添加一些 Python 代码(运行时版本:3.9):
import json
import boto3
bedrock = boto3.client('bedrock-runtime')
def lambda_handler(event, context):
prompt = event['queryStringParameters']['prompt']
response = bedrock.invoke_model(
body=json.dumps({
"prompt": f"{prompt}",
"max_length": 300,
"temperature": 0.7,
"k": 0,
"p": 0.75,
"frequency_penalty": 0,
"presence_penalty": 0
}),
modelId="arn:aws:bedrock::account:model/claude-v2-20221215"
)
output = json.loads(response['body'].read().decode('utf-8'))
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"code": output[0]["generated_text"]})
}
步骤 3:部署用于代码生成的 API
- 转到 API 网关 并选择 HTTP API 选项。
- 将其与代码生成器集成。
- 部署 API 并获取 交互的调用 URL 。
使用 Amazon Bedrock 的最佳实践
使用 Amazon Bedrock时 ,您需要关注安全性、成本和性能。遵循这些最佳实践,您可以确保您的 AI 应用安全、高效且经济实惠。
1. 数据安全和隐私
理想情况下,您应该保护数据隐私,因为 AI 模型通常会处理敏感的用户数据,因此安全性至关重要。为了在使用 AWS Bedrock 时保护数据,请遵循以下一些实践:
- 使用 IAM 角色和策略: 遵循 最小权限原则 来限制对 Bedrock API 和数据存储的访问。这意味着只授予用户必要的权限,不多不少。
- 加密数据: 您可以使用 AWS Key Management Service (KMS) 来保护敏感数据,无论是在存储数据时还是在发送数据时。
- 监控和审计访问: 启用 CloudWatch 和 AWS Config ,以跟踪谁访问了 AI 模型、数据和日志;以及它们是如何被访问的。
- 数据掩码: 在将数据发送到 Bedrock 之前,请删除任何个人身份信息以降低风险。
2. 成本优化(基石使用和费用管理)💸
AWS Bedrock 采用 按需付费的 定价模式,因此有效控制成本至关重要。您将根据实际使用量付费。以下是如何使用 AWS Bedrock 优化成本:
- 选择合适的地基型号: 不同型号的价格不同;选择最符合您的需求和预算的型号。
- 优化 API 调用: 尽可能使用缓存和批量处理来减少不必要的 API 请求。
- 监控使用情况: 使用 AWS Cost Explorer 和 AWS Budgets 跟踪您的支出,并设置警报以防任何意外的成本增加。
- 使用自动扩展: 将 Bedrock 与 AWS Lambda 一起使用时,调整请求数量以减少不必要的 API 调用。
3. 偏见与公平
人工智能模型可能会根据训练数据产生偏见,这可能会导致问题。为了确保公平:
- 检查模型响应: 定期使用提示测试模型的输出,以识别任何偏差或错误。
- 使用多样化的数据进行微调: 调整模型时,确保数据包含各种群体和观点。
4. 性能调优
为了提高响应速度和整体性能,请遵循以下做法:
- 调整 API 参数: 调整诸如 `and`
temperature和 `to` 之类的设置maxTokens以获得最佳结果。 - 使用 GPU 优化的基础设施: 如果您要部署自定义模型,请使用 AWS Inferentia 来提高性能。
- 负载均衡请求: 如果流量很大,请使用 AWS 应用程序负载均衡器 来更有效地分配请求。
- 降低延迟:使用AWS 全球加速器 或 AWS 边缘服务 将应用程序部署得更靠近用户 。
结论
AWS Bedrock 提供来自亚马逊和其他基础设施的可扩展基础模型,无需用户自行训练模型和管理基础设施,从而简化了 AI 集成。为了获得最佳效果,开发人员可以更专注于安全性、成本效益和性能提升,而无需手动操作。
为了持续探索 AWS Bedrock 的奥妙,开发者应该尝试不同的模型、调整输出结果,并与其他 AWS 服务进行连接。持续关注 Amazon Bedrock 的指南、博客和其他资源,将有助于充分发挥 Bedrock 的优势,并激发人工智能应用领域的新思路。
在你离开之前……🥹
感谢您抽出时间了解如何使用 AWS Bedrock 构建 AI 应用程序。如果您觉得本文对您有所帮助,请考虑创建账户并 加入社区来支持 Microtica 。您的支持有助于我们不断改进并为开发者社区提供更多宝贵资源!
