借助迪杰斯特拉算法寻找最短路径
如果你花足够的时间阅读编程或计算机科学方面的书籍,你很可能会反复遇到相同的概念、术语和名称。随着时间的推移,其中一些会变得越来越熟悉。自然而然地,有时甚至无需你付出太多努力,你就会开始了解所有这些事物的含义。这是因为你逐渐理解了某个概念,或者你反复阅读某个短语,最终真正理解了它的含义。
然而,有些概念和定义却很难理解。这些概念和定义你觉得自己应该知道,但你接触得不够多,所以无法真正理解。
那些我们感觉自己应该了解,却始终没能真正去学习的课题,往往是最令人望而生畏的。入门门槛极高,对于几乎一无所知的领域,理解起来更是难上加难。对我而言,迪杰斯特拉算法就是这样一个令我望而生畏的课题。我以前总是听到有人提起它,却从未真正接触过它,因此既缺乏相关的背景知识,也没有任何工具去尝试理解它。
值得庆幸的是,在撰写本系列文章的过程中,一切都发生了改变。多年来,我一直对迪杰斯特拉算法感到恐惧和焦虑,但现在我终于理解了它。希望读完这篇文章后,你也能有所领悟!
那些让你心神不宁的图表
在真正深入了解迪杰斯特拉 (Dijkstra) 的著名算法之前,我们需要先了解一些重要的信息,这些信息在我们后续的学习过程中会用到。
在本系列课程中,我们逐步积累了不同数据结构的知识。我们不仅学习了各种图遍历算法,还掌握了图论的基础知识,以及如何在代码中实际表示图。我们已经知道图可以是定向图、无向图,甚至可能包含环。我们也学习了如何使用广度优先搜索和深度优先搜索这两种截然不同的策略来遍历图。
在我们理解图以及各种图结构的旅程中,有一种图我们一直忽略了……直到现在。是时候让我们真正认识一下加权图了!

加权图的有趣之处在于,它与图是有向图、无向图或包含环关系不大。本质上,加权图是一种边具有某种关联值的图。附加到边上的值赋予了边“权重”。

表示单条边“权重”的一种常见方法是将其视为两个节点之间的成本或距离。换句话说,从节点 a 到节点 b 需要付出一定的成本。
或者,如果我们把节点想象成地图上的位置,那么权重就可以表示节点 a 和 b 之间的距离。继续沿用地图的比喻,边的“权重”也可以表示可以在两个节点 a 和 b 之间运输或移动的物品的容量。
例如,在上面的例子中,我们可以确定节点 c 和 b 之间的成本、距离或容量的权重为 8。

在本系列文章中,加权图与我们目前所讨论的无权图之间的唯一区别在于边的权重。
事实上,我们或许已经能够想象如何表示这种加权图了!加权图可以用邻接表来表示,并添加一个额外的属性:一个用于存储图中每条边的成本/权重/距离的字段。根据我们之前对图表示的研究,我们还记得,邻接表中的边位于“列表”部分。
对于图中的每一条边,我们将调整存储这些边的链表的定义,使得链表中的每个元素可以包含两个值,而不仅仅是一个。这两个值分别是对应节点的索引(用于确定这条边连接到哪里)以及与这条边关联的权重。
以下是同一个加权图的邻接表格式表示。
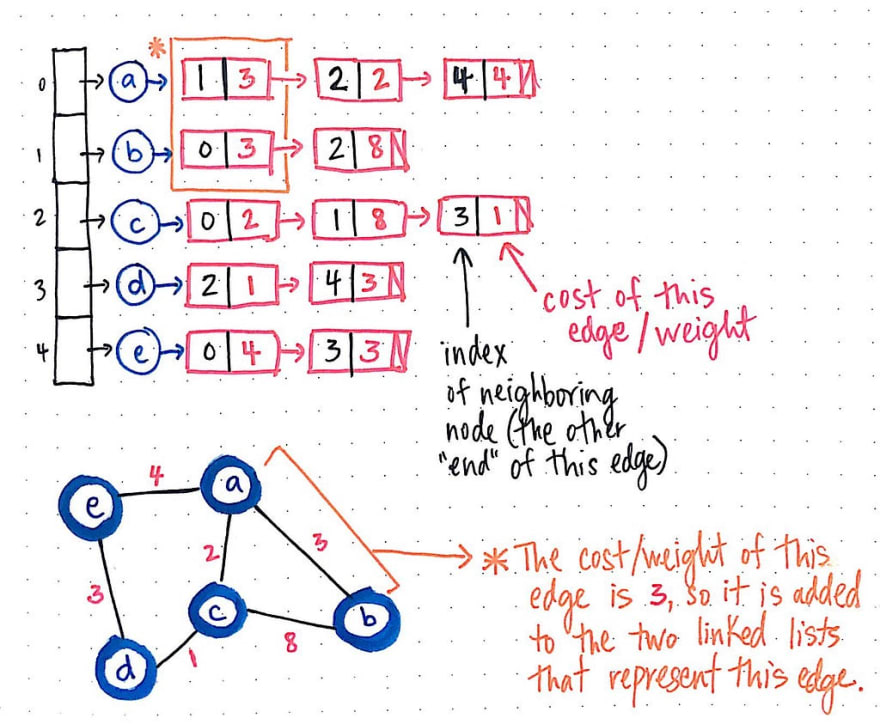
首先,我们会注意到这个图表示的两个特点:首先,由于这是一个无向图,节点 a 和 b 之间的边会出现两次——一次在节点 a 的边列表中,一次在节点 b 的边列表中。其次,无论这条边出现在哪个节点的边列表中,链表元素中都会存储一个成本/权重,该成本/权重指向相邻节点(在本例中为 a 或 b)。
好的,所以目前还没有什么太复杂、需要我们去理解的事情,对吧?
这里,图表的权重开始让事情变得稍微复杂一些:
当我们需要考虑所经过的边的权重时,找到两个节点之间的最短路径就变得更加棘手了。
我们来看一个例子,这样就更容易理解了。在下面这个简单的有向加权图中,我们有一个包含三个节点(a、b 和 c)和三条有向加权边的图。

观察这张图,我们或许能够迅速——几乎毫不犹豫地——确定从节点 a 到节点 b 的最快路径。a 和 b 之间有一条边,所以这一定是最快的路径,对吧?
不完全是这样。考虑到这些边的权重,我们再深入分析一下。如果我们走从节点 a 到节点 b 的路径,成本是 5。但是,如果我们走从节点 a 到节点 c 再到节点 b 的路径,成本就只有 3。
但为什么是 3 呢?虽然直觉上它看起来像是一条更长的路径,但如果我们把从节点 a 到节点 c 再从节点 c 到节点 b 的边数加起来,就会发现总成本是 2 + 1,也就是 3。这可能意味着我们走了两条边,但成本 3 当然比成本 5 更划算!
在我们这个三节点示例图中,我们可以比较容易地找到起点和终点之间的两条可能路径。但是,如果我们的图更大呢?比如说有二十个节点?考虑到加权图的权重,找到最短路径就没那么容易了。如果图更大呢?事实上,我们处理的大多数图都远大于二十个节点。那么,用穷举法来解决这个问题,可行性、可扩展性和效率究竟如何呢?
答案是,这不太可行。而且也没什么乐趣!这时,迪杰斯特拉就派上用场了。
迪杰斯特拉游戏的规则
迪杰斯特拉算法的独特之处有很多,我们很快就会在理解其工作原理的过程中看到这些原因。但最令人惊讶的是,该算法并非仅用于寻找图数据结构中两个特定节点之间的最短路径。只要所有节点都可从起始节点到达,迪杰斯特拉算法就可以用来确定图中任意一个节点到该图数据结构中所有其他节点的最短路径。

该算法会持续运行,直到图中所有可达顶点都被访问完毕。这意味着我们可以运行 Dijkstra 算法,找到任意两个可达节点之间的最短路径,然后将结果保存下来。只需运行一次Dijkstra 算法,我们就可以反复查找算法结果——而无需实际运行算法本身!只有当图的数据结构发生变化时,才需要重新运行 Dijkstra 算法,以确保我们仍然拥有针对特定数据结构的最新最短路径。
那么,迪杰斯特拉算法究竟是如何运作的呢?是时候一探究竟了!
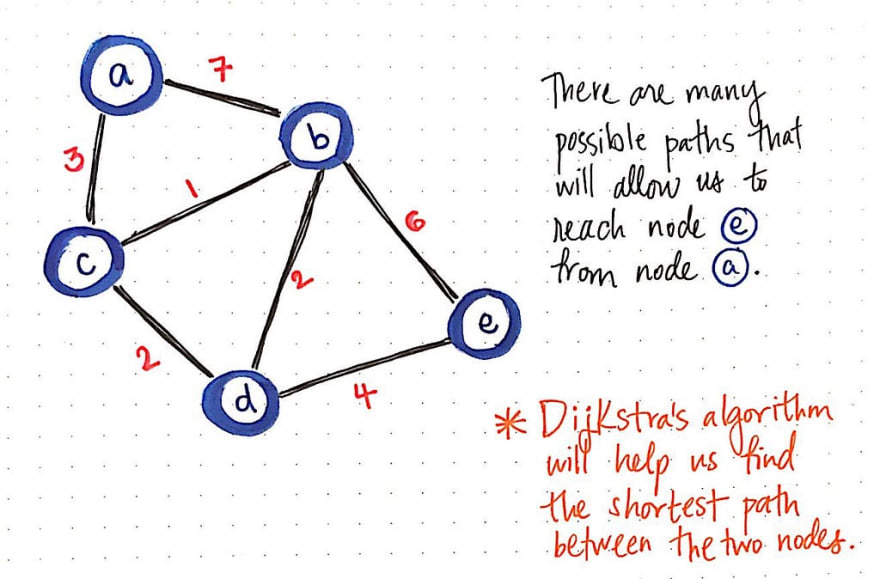
考虑上图所示的加权无向图。假设我们要找到从节点 a 到节点 e 的最短路径。我们知道起点是节点 a,但我们不知道是否存在一条到达节点 a 的路径,也不知道是否存在多条路径!总之,我们不知道哪条路径是到达节点 e 的最短路径,甚至不知道是否存在这样的路径。
Dijkstra 算法确实需要一些初始设置。但在进行设置之前,我们先快速了解一下运行 Dijkstra 算法的步骤和规则。在我们的示例图中,我们将节点 a 作为起始节点。然而,Dijkstra 算法的运行规则可以抽象出来,以便应用于我们将要遍历和访问的每一个节点,从而找到最短路径。

摘要后的规则如下:
- 每次我们准备访问一个新节点时,我们都会选择已知距离/成本最小的节点作为首选访问对象。
- 一旦我们移动到要访问的节点,我们将检查它的每一个相邻节点。
- 对于每个相邻节点,我们将通过对从 起始顶点到我们正在检查的节点的边的成本求和来计算相邻节点的距离/成本。
- 最后,如果到某个节点的距离/成本小于已知距离,我们将更新我们文件中该顶点的最短距离。
这些指令是我们的黄金法则,我们将始终遵循这些法则,直到算法运行完毕。那么,让我们开始吧!
首先,我们需要初始化一些东西,以便在算法运行时跟踪一些重要信息。
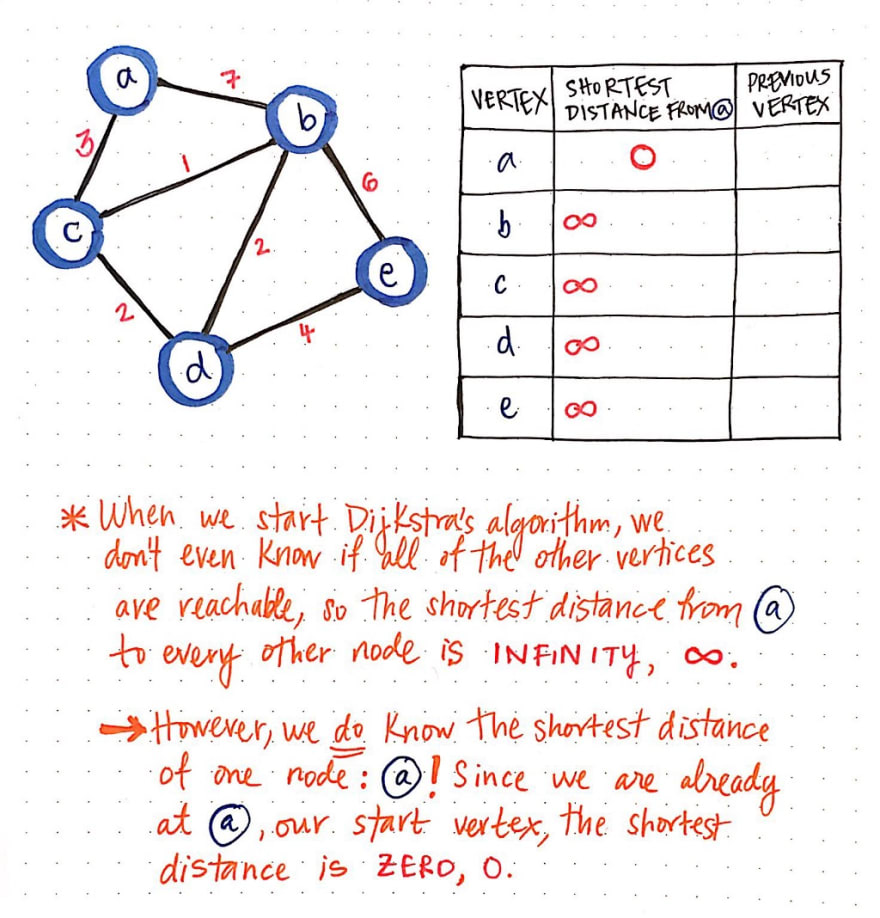
我们将创建一个表格来记录图中每个顶点的最短已知距离。我们还会记录在“检查”当前顶点之前,我们之前经过的顶点。
一旦我们把表格设置好,就需要给它赋值。当我们开始执行Dijkstra算法时,我们一无所知!我们甚至不知道列出的其他顶点(b、c、d和e)是否都能从起始节点a到达。
这意味着,当我们最初出发时,“从节点 a 出发的最短路径”将是无穷大(∘)。然而,当我们出发时,我们确实知道一个节点的最短路径,而且只有一个节点:当然是节点 a,也就是我们的起始节点!因为我们从节点 a出发,所以我们一开始就已经在那里了。因此,从节点 a 到节点 a 的最短距离实际上就是 0!
现在我们已经初始化了表格,在运行这个算法之前,还需要一样东西:一种跟踪哪些节点已经访问过、哪些节点尚未访问的方法!我们可以使用两个数组结构轻松实现这一点:一个已访问数组和一个未访问数组。

开始时,我们实际上还没有访问过任何节点,因此我们所有的节点都存在于未访问数组中。
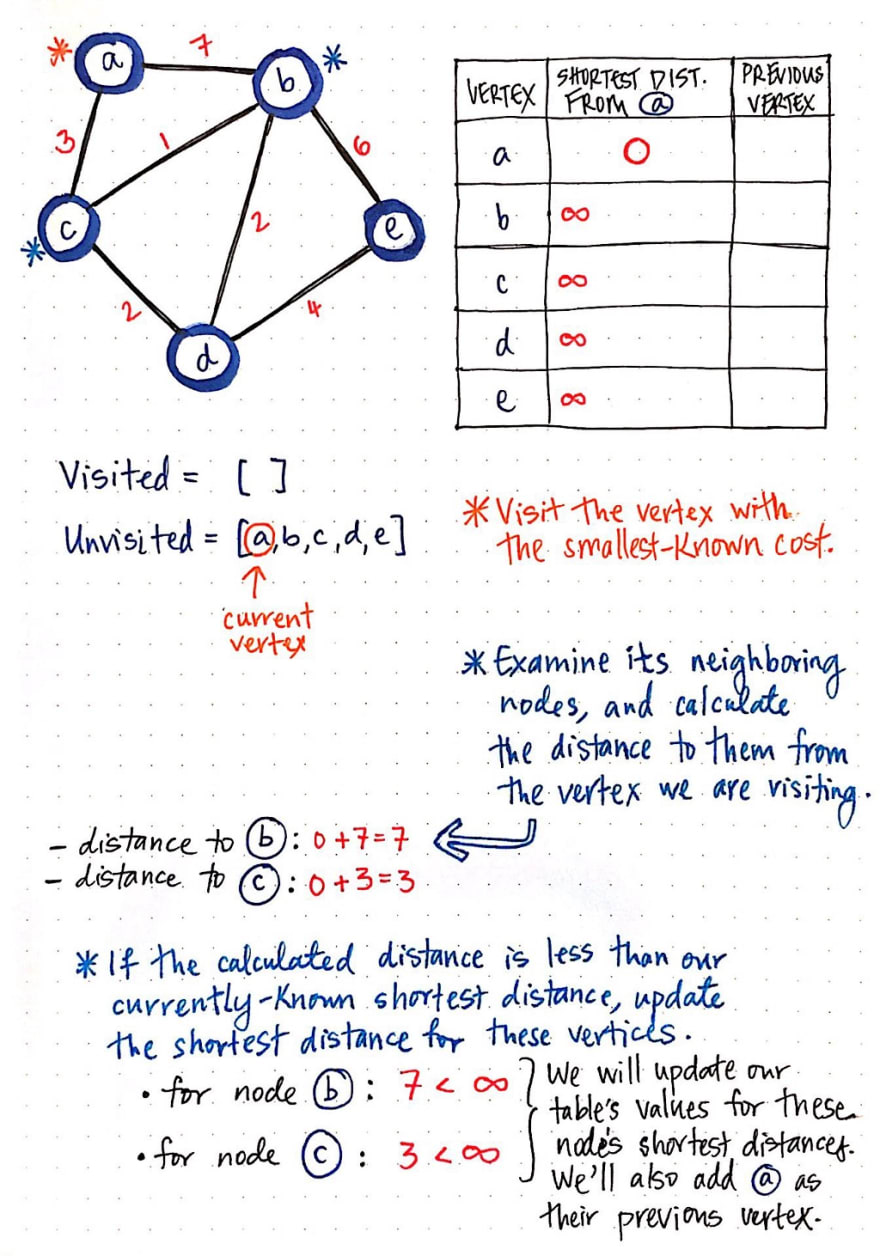
好了,现在一切就绪!让我们开始吧。还记得我们之前提到的四条规则吗?我们将一步一步地遵循这些规则,处理图中的每个顶点。
首先,我们将访问已知成本/距离最小的顶点。我们可以查看表示从 a 到其他顶点最短距离的那一列。目前,除了 a 本身之外,每个顶点的距离都是无穷大(∅)!因此,我们将访问节点 a。
接下来,我们将检查它的相邻节点,并计算当前观察的顶点(即 a)到这些节点的距离。到节点 b 的距离是 a 的成本加上到达节点 b 的成本:在本例中为 7。类似地,到节点 c 的距离是 a 的成本加上到达节点 c 的成本:在本例中为 3。
最后,如果计算出的距离小于我们目前已知的相邻节点之间的最短距离,我们将用新的“最短距离”更新表中的值。目前,表中显示从 a 到 b 的最短距离为 7,从 a 到 c 的最短距离也为 3。由于 7 小于无穷大,3 也小于无穷大,我们将节点 b 的最短距离更新为 7,节点 c 的最短距离更新为 3。我们还需要更新 b 和 c 的前一个顶点,因为我们需要记录路径的来源!我们将 b 和 c 的前一个顶点更新为 a,因为这是我们刚刚到达的顶点。
现在,我们已经检查完了节点 a 的所有邻居,这意味着我们可以将其标记为已访问!接下来检查下一个节点。

同样,我们会寻找尚未访问且成本最小的节点。在本例中,节点 c 的成本为 3,是所有未访问节点中成本最小的。因此,节点 c 成为我们的当前顶点。
我们将重复之前的步骤:检查节点 c 的未访问邻居节点,并计算从起点节点 a 到它们的最短路径。节点 c 尚未访问的两个邻居节点是节点 b 和节点 d。到节点 b 的距离是节点 a 的成本加上从节点 c 到节点 b 的成本:在本例中为 4。到节点 d 的距离是节点 a 的成本加上从节点 c 到节点 d 的成本:在本例中为 5。
现在,让我们把这两条“最短距离”与表格中的值进行比较。目前,到节点 d 的距离是无穷大,所以我们肯定找到了一条成本更低的路径,其值为 5。但是到节点 b 的距离呢?表格中到节点 b 的距离目前标记为 7。但是,我们找到了一条到达 b 的更短路径,这条路径经过节点 c,成本仅为 4。所以,我们将用这些更短的路径更新表格!
我们还需要将顶点 c 添加为节点 d 的前一个顶点。注意,节点 b 已经有一个前一个顶点,因为我们之前找到了一条路径,但现在我们知道这条路径实际上并不是最短的。不用担心……我们只需划掉节点 b 的前一个顶点,并将其替换为我们现在知道的路径更短的顶点:节点 c。

好了,现在我们已经访问了节点 a 和节点 c。那么,接下来我们要访问哪个节点呢?
同样,我们将访问成本最小的节点;在这种情况下,看起来是节点 b,成本为 4。
我们将检查它未访问的邻居(它只有一个,即节点 e),并计算从原节点经当前顶点 b到 e 的距离。
如果我们把 b 的成本(即 4)与从 b 到 e的成本相加,就会发现总成本为 6。因此,从起始顶点经当前节点到 e 的最短已知距离的总成本为 10。
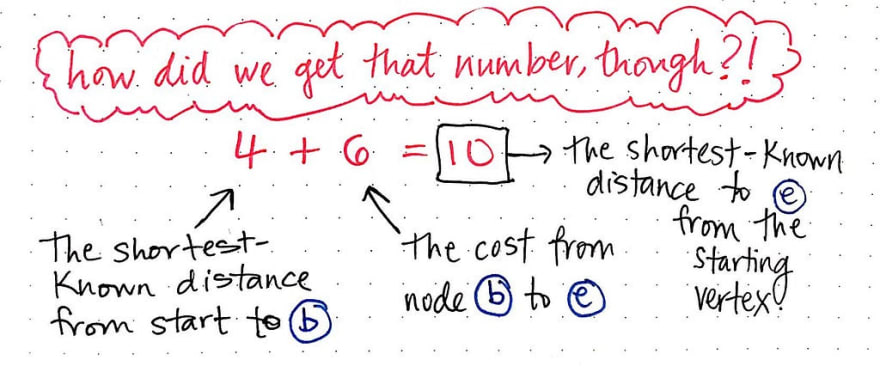
那么,我们是如何得到这个数字的呢?乍一看可能有点复杂,但我们可以把它分解成几个部分。记住,无论我们查看的是哪个顶点,我们始终要计算从起点到当前顶点的最短已知距离之和。简单来说,我们要查看表格中的“最短距离”值,在本例中,该值为 4。然后,我们要查看从当前顶点到我们正在检查的相邻顶点的成本。在本例中,从 b 到 e 的成本为 6,所以我们将其加到 4 上。
因此,6 + 4 = 10 是我们从起始顶点到节点 e 的最短已知距离。
迪杰斯特拉魔术背后的秘密
我们将继续对每个未访问的顶点执行相同的步骤。在这个图中,我们要检查的下一个节点是 d,因为它是所有未访问节点中距离最短的。节点 d 的邻居中只有一个未访问,即节点 e,因此我们只需要检查 e 即可。
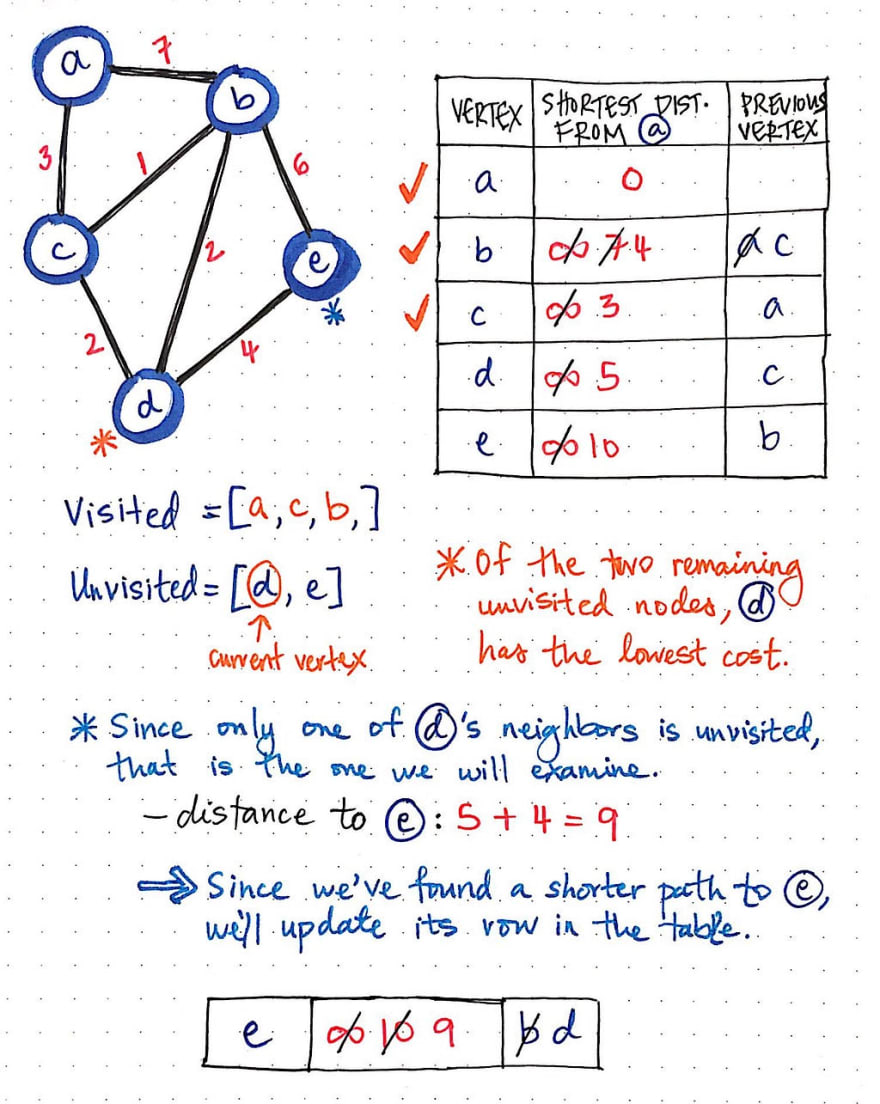
当我们把节点 d 到 e 的距离和从节点 d 到 e 的成本相加时,会发现最终结果是 9,小于 10,也就是当前到达节点 e 的最短路径值。我们将更新表格中节点 e 的最短路径值和之前的顶点值。

最后,我们只剩下一个节点需要访问:节点 e。
然而,很明显,我们在这里实际上什么也做不了!节点 e 的任何邻居都不需要检查,因为其他所有顶点都已经访问过了。
我们只需要将节点 e 标记为已访问即可。现在,我们已经完全完成了在这个图上运行 Dijkstra 算法的操作!
我们在更新和修改表格数值的过程中,已经删除了很多信息。现在让我们来看一个更简洁美观的表格版本,其中只包含该算法的最终结果。

从这张表格来看,可能不太容易看出,但实际上我们已经掌握了从起始节点 a 出发的所有最短路径,触手可及。我们之前学过,Dijkstra 算法只需运行一次,就可以重复使用所有结果——前提是图的结构不变。这正是该特性强大的地方。我们最初的目标是找到从a 到 e 的最短路径。但是,这张表格可以让我们查找所有最短路径!

要查找此表中任何最短路径的方法,是沿着我们之前的步骤,沿着任何节点的“前一个顶点”返回到起始节点。
例如,假设我们突然决定要找到从 a 到 d 的最短路径。无需再次运行 Dijkstra 算法——我们已经拥有所需的所有信息,就在这里!
我们将使用栈数据结构,从节点 d 开始,并将其压入栈中。然后,我们查看节点 d 的前一个顶点,即节点 b。我们将节点 b 也压入栈中。类似地,我们查看节点 b 的前一个顶点(节点 c),并将其添加到栈中,然后查看节点 c 的前一个顶点,即节点 a,也就是我们的起始顶点!
当我们沿着路径一路向上追溯到起始顶点后,就可以从栈中弹出每个顶点,得到的顺序是:a–c–b–d。事实证明,这正是从节点 a 到节点 d 成本/距离最低的路径!是不是很棒?

在很多方面,Dijkstra 算法是对我们熟悉的广度优先图遍历算法的一种更精细的改进。主要区别在于它更智能,并且能够很好地处理加权图。但是,如果我们观察 Dijkstra 算法的可视化过程(例如此处所示的动画),我们会发现它本质上类似于广度优先搜索,只是搜索范围更广,而不是深入探索某一条特定路径。
Dijkstra 算法在实际应用中最常见的例子是路径查找问题,例如确定方向或在 Google 地图上查找路线。

然而,要在谷歌地图上找到路径,Dijkstra 算法的实现需要比我们今天创建的版本更加智能。我们在这里实现的 Dijkstra 算法版本仍然不如大多数实际应用的版本智能。想象一下,这不仅是一个加权图,还需要计算交通状况、路况、道路封闭和施工等因素。
如果这一切让你觉得难以理解,别担心……这确实很复杂!事实上,这是一个难题,就连迪克斯特拉本人也难以用实例完美地阐释。原来,当艾兹格·W·迪克斯特拉在1956年首次思考寻找最短路径的问题时,他很难找到一个非计算机领域人士也能轻松理解的问题(及其解决方案)!最终,他确实找到了一个很好的例子来展示找到最短路径的重要性。他选择的例子——你猜对了!——是一张地图。事实上,当他最初设计算法时,他是在一台名为ARMAC的计算机上实现的。他使用包含荷兰各地城市的交通地图作为示例,来展示他的算法是如何工作的。
在生命的最后阶段,迪杰斯特拉接受了一次采访,详细讲述了他如何构思出如今闻名遐迩的算法:
从鹿特丹到格罗宁根的最短路线是什么?这是我大约花了20分钟设计的最短路径算法。一天早上,我和我的未婚妻逛街,我们很累,就坐在咖啡馆的露台上喝咖啡。我当时就在想,我能不能设计出这条路线,然后我就设计出了最短路径算法。
那么这个故事告诉我们什么呢?我确信答案很简单:没有什么问题是一杯香浓的咖啡解决不了的。
资源
无论好坏,Dijkstra 算法都是计算机科学领域最著名的图遍历方法之一。坏消息是,由于相关的参考文献众多,理解它的工作原理有时会让人感到畏惧。好消息是,网上有很多资源——你只需要知道从哪些入手!以下是我最喜欢的一些资源。
- 图数据结构——Dijkstra 最短路径算法,Kevin Drumm
- 迪杰斯特拉算法,计算机爱好者
- 图的 Dijkstra 最短路径算法,Sesh Venugopal
- 一种用于计算最短路径的单源最短路径算法,作者:伊莱亚娜·斯特雷努教授
- 关于图论中两个问题的注释,E.W. Dijkstra
文章来源:https://dev.to/vaidehijoshi/finding-the-shortest-path-with-a-little-help-from-dijkstra-cmi