[AutoBE] 我们为 Vibe Coding 开发了 AI 友好型编译器,实现了 100% 的构建成功率(开源,类似 AWS Kiro)
由 Mux 赞助的 DEV 全球展示挑战赛:展示你的项目!
前言
视频播放速度加快了;实际播放时间大约需要20-30分钟。
我们荣幸地向AutoBE您介绍。AutoBE这是一个由韩国人工智能初创公司 Wrtn Technologies 开发的开源项目,它是一个 Vibe 编码代理,可以自动生成后端应用程序。
的关键特性之一AutoBE是它始终能生成编译成功率达 100% 的代码。其秘诀在于我们自主研发的编译器系统。通过我们自主开发的编译器,我们支持 AI 生成类型安全的代码;当 AI 生成错误代码时,编译器会检测到错误并提供详细的反馈,引导 AI 生成正确的代码。
通过这种方法,AutoBE后端应用程序的编译成功率始终保持在 100%。当 AI 通过函数调用构建 AST(抽象语法树)数据时,我们专有的编译器会对其进行验证,提供反馈,并最终生成完整的源代码。
什么是AI函数调用? AI函数调用是一种利用人工智能根据预定义的函数模式生成结构化数据的技术。与一般的文本生成不同,它生成的是符合特定类型和格式的JSON数据,可以直接被程序使用。
瀑布式编译器系统
大纲

AutoBE后端应用程序的生成基于瀑布模型的编译器系统。整个过程包含五个顺序阶段,每个阶段都由专门的代理负责。
外观控制器负责协调整个流程,而各个功能代理则按顺序执行任务。分析代理分析用户需求以创建详细的功能规范,Prisma代理基于这些规范设计数据库模式,接口代理定义API接口,测试代理生成端到端测试代码,最后,实现代理编写实际的API实现代码。
每个代理的输出都通过相应的专用编译器进行验证。Prisma 代理的输出由我们自主开发的 Prisma 编译器验证,Interface 代理的输出由 OpenAPI 验证器验证,Test 和 Realize 代理的 TypeScript 代码由 TypeScript 编译器验证。这种分阶段验证系统是保证 100% 编译成功率的核心机制。
Prisma DB 模式编译器
数据库设计编译器。
- 编译器结构
- 生成结果
AutoBE在设计数据库时,采用自主开发的数据库编译器。
首先,它通过AI函数调用(或结构化输出)创建一个抽象语法树(AST)结构AutoBePrisma.IFile。然后,它分析AI创建的数据,以检查逻辑错误或类型错误。
如果发现逻辑错误,会将错误信息连同IAutoBePrismaValidation详细原因一起返回给人工智能,指导人工智能AutoBePrisma.IFile在下次函数调用中生成正确的数据。主要的逻辑错误情况包括:
- 重复错误:文件名、模型名称、字段名称定义重复。
- 循环引用:两个模型相互引用(作为外键)的交叉依赖关系。
- 不存在的引用:外键指向不存在的目标模型的情况
- 索引配置错误:在不存在的字段上创建索引,重复的索引定义
- 数据类型不匹配:将 GIN 索引应用于非字符串字段
- 字段名与表名相同:可能导致因规范化错误而造成的混淆
如果发现类型错误,也会以 的形式返回给 AI IValidation,引导 AI 生成具有正确类型的数据。
最后,当AutoBePrisma.IFile生成的数据正确无误,没有任何逻辑或类型错误时,它会被转换为 Prisma DB 模式(代码生成)。同时,还会生成实体关系图 (ERD) 和文档prisma-markdown,帮助用户理解其数据库设计。
生成的 Prisma 模式文件包含每个表和字段的详细描述性注释。这些注释不仅限于简单的代码文档,它们prisma-markdown在生成实体关系图 (ERD) 和文档时会被直接使用,成为数据库设计文档的核心内容。因此,开发人员不仅可以从代码层面,还可以通过可视化的 ERD 图清晰地理解每个表和字段的作用。
OpenAPI 文档编译器
用于 API 接口设计的编译器。
AutoBE在设计 API 接口时,采用自主开发的 OpenAPI 编译器。
这个 OpenAPI 编译器首先会生成一个类型为 的抽象语法树 (AST) 结构AutoBeOpenApi.IDocument,该结构是通过 AI 函数调用创建的。然后,它会分析这些数据,如果发现逻辑错误或类型错误,则会将详细的原因返回给 AI,从而指导 AI 生成正确的AutoBeOpenApi.IDocument数据。
AI成功生成完美无瑕的API后AutoBeOpenApi.IDocument,AutoBE将其转换为官方OpenAPI v3.1规范OpenApi.IDocument结构。然后,进一步将其转换为TypeScript/NestJS源代码(代码生成),完成API接口的实现。
生成的 TypeScript/NestJS 源代码包含 API 控制器类和 DTO(数据传输对象)类型,其中每个 API 控制器方法都是一个模拟方法,它仅使用typia.random<T>()函数生成指定返回类型的随机值。因此,生成的 APIAutoBE实际上并不具备功能,但它们完成了 API 接口设计和实现的基础工作。
所有生成的控制器函数和 DTO 类型都包含详细的 JSDoc 注释。每个 API 端点的用途、参数描述和返回值含义都得到了清晰的文档说明,使开发人员能够轻松理解 API 的用途和用法。
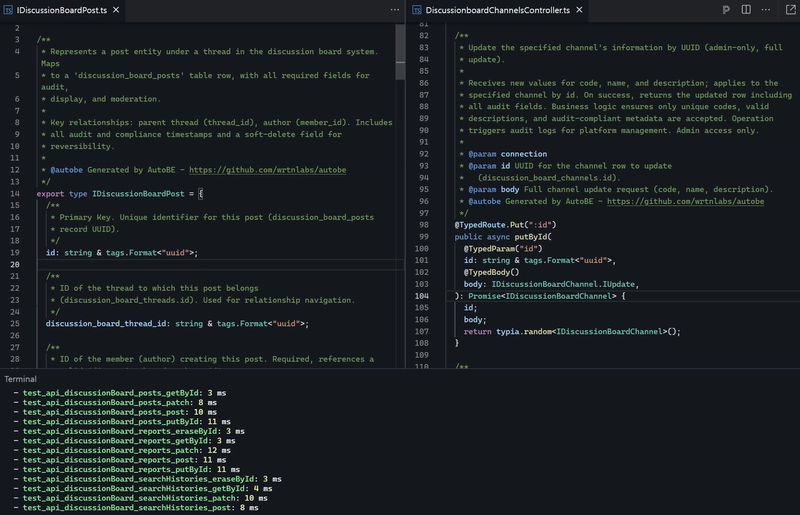
端到端测试功能编译器
用于生成端到端测试程序的编译器。
- 编译器结构
- 提示结构
- 生成结果:https://github.com/wrtnlabs/autobe-example-bbs
AutoBE在生成 E2E 测试代码时,使用自行开发的编译器。
这个端到端测试编译器有一个名为 AST(抽象语法树)的结构AutoBeTest.IFunction,它是通过调用人工智能函数构建的。然后,它会分析这些数据,如果发现逻辑错误或类型错误,则会将详细的原因返回给人工智能,指导人工智能生成正确的AutoBeTest.IFunction数据。
AI成功生成无误AutoBeTest.IFunction数据后,AutoBE将其转换为TypeScript源代码(代码生成)。然后,测试代理将生成的每个端到端测试函数与接口代理生成的代码相结合,从而完成一个新的后端应用程序。
当 E2E 测试函数调用后端服务器 API 函数时,它们会使用为后端服务器 API 生成的 SDK(软件开发工具包)来确保 API 函数调用的类型安全。
每个生成的端到端测试函数都包含详细的注释,描述了测试场景和目的。API 的调用顺序、每一步验证的内容以及预期结果都得到了清晰的记录,从而使用户能够轻松理解测试代码的意图。
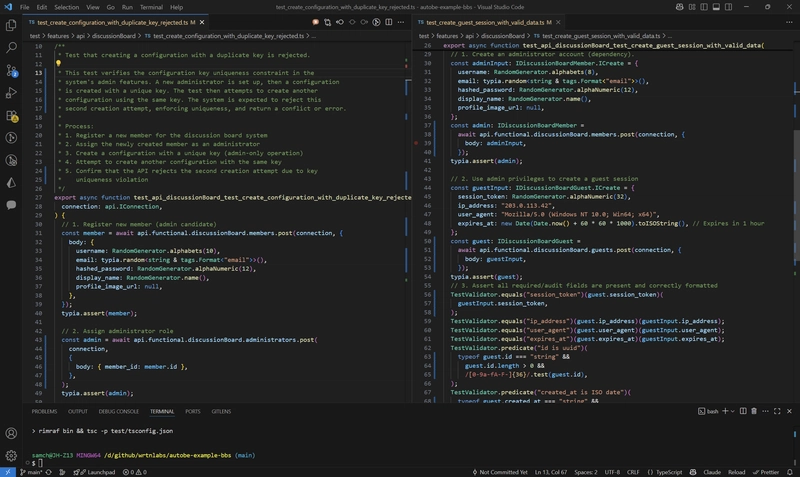
当后端应用程序堆栈由
AutoBETypeScript/NestJS 生成时,AutoBE它不会AutoBeTest.IFunction通过 AI 构建结构化输出数据。它采用结构化AI输出,由AI针对给定的API端点设计场景,编写测试代码草稿,然后进行审查和修改,最终生成代码。AI编写的代码随后通过TypeScript编译器API进行验证。如果编译失败,系统会向AI返回详细的失败原因,指导其生成正确的代码。
然而,这种方法仅适用于 TypeScript/NestJS 技术栈。对于其他语言和技术栈,
AutoBeTest.IFunction数据仍然需要通过 AI 函数调用来构建和编译。typia.llm.parameters<{ scenario: string; // test scenario draft: string; // the draft code written by AI review: string; // self-review about the draft code final: string; // the final code after review }, "chatgpt">();
其他资源
TypeScript 编译器
TypeScript编译器嵌入。
AutoBEAutoBE嵌入 TypeScript 编译器,对 AI 或内置编译器生成的 TypeScript 源代码执行最终验证。
AI函数调用编译器
用于人工智能函数调用和验证反馈的编译器。
- 编译器函数
typia.llm.application<App, Model>():AI 函数调用typia.llm.parameters<Params, Model>()人工智能结构化输出
- AST结构
能够以 100% 的编译成功率生成后端应用程序的秘诀AutoBE在于其自主开发的编译器,以及通过 AI 函数调用创建所有 AST(抽象语法树)结构。
然而,与世界上所有编译器抽象语法树(AST)结构一样,它们本质上是具有递归引用关系的树状结构,其层次结构和复杂性难以言表。虽然用于人工智能函数调用或结构化输出的 JSON 模式通常由人工编写,但AutoBE编译器的 AST 结构过于庞大、复杂和精细,人工编写 JSON 模式是不可能的。
此外,用于 AI 函数调用的 JSON 模式在不同的 AI 厂商之间规范不一。OpenAI 和 Gemini 甚至创建了自己的规范,而不是使用标准的 JSON 模式定义;而 Claude 虽然遵循标准的 JSON 模式定义,却讽刺地在其 MCP 指南中使用了过时的 JSON 模式 v7 规范来定义类型。AI 函数调用的 JSON 模式规范可谓一片混乱。
因此,虽然通常建议在使用 AI 函数调用或结构化输出创建 AI 代理时避免使用复杂类型并简单地定义它们,但却AutoBE无法这样做,因为它必须表达编译器 AST 结构。
Gemini 不支持联合类型,因此在以下情况下无法使用
AutoBE。

为了解决这个问题,AutoBE团队开发人员创建了typiaTypeScript 编译器插件库,该库可以自动从 TypeScript 源代码生成 AI 函数调用和结构化输出模式,并将其集成到 中AutoBE。
当您指定目标类型和 AI 模型(如下所示)时,typia系统会自动创建 AI 函数调用和结构化输出模式。此外,调用时typia.llm.application<Class, Model>(),它还会为该类类型中的所有方法生成类型验证反馈的验证器函数。
AutoBE已实现 Vibe 编码代理,通过积极利用内部和外部编译器技术,编译成功率达到 100%。
typia.llm.parameters<AutoBeOpenApi.IDocument, "chatgpt">()typia.llm.parameters<AutoBeOpenApi.IDocument, "claude">()typia.llm.parameters<AutoBeOpenApi.IDocument, "llama">()
后端堆栈
TypeScript / NestJS / Prisma
AutoBE目前支持 TypeScript/NestJS/Prisma 后端技术栈组合。
选择TypeScript 的主要原因是它的编译器和 API 完全开源,并且可以通过插件系统进行扩展。为了实现AutoBE我们核心的基于编译器的架构,我们需要深度利用语言自身的编译器,而 TypeScript 完美地满足了这些需求。此外,它强大的类型系统能够保证 AI 生成代码的类型安全,这对于实现 100% 编译成功率的目标至关重要。
NestJS通过与Nestia的结合实现了AutoBE其核心功能。Nestia 是一款分析 NestJS 源代码并自动生成客户端 SDK 库的工具,使得NestJS 生成的端到端测试程序能够执行完全类型安全的 API 调用。诸如 URL 拼写错误、参数类型不匹配和响应结构更改等典型的 REST API 测试问题都能在编译时被检测到,从而显著提高测试代码的可靠性。AutoBE
Prisma负责数据库模式管理和类型安全查询的生成。Prisma 的模式定义语言结构清晰,便于AutoBETypeScript 编译器进行解析和验证。生成的 TypeScript 客户端也能确保数据库操作的完全类型安全。此外,其迁移系统支持对数据库模式变更进行系统化管理,有助于维护开发环境和生产环境之间的一致性。
AutoBE这三种技术的结合是实现“基于编译器的代码生成”和“100% 编译成功”目标的最佳选择。
其他语言和框架
AutoBE的架构设计为与语言和框架无关。其核心原则是,AI 通过函数调用生成抽象语法树 (AST) 结构,然后将其转换为相应语言的源代码。
目前,我们仅支持 TypeScript/NestJS/Prisma 组合,但理论上完全可以扩展到其他语言和框架。例如,要扩展到 Java/Spring Boot、Python/FastAPI 或 Go/Gin 等组合,我们需要为每种语言定义合适的抽象语法树 (AST) 结构,并开发相应的编译器或验证系统。
然而,针对特定语言的扩展需要大量的开发投入。我们必须深入了解每种语言独特的类型系统、编译器特性和框架结构,并构建能够保证AutoBE“100% 编译成功”这一核心价值的验证系统。目前,我们专注于提升 TypeScript 技术栈的完整性,未来将根据用户需求和项目发展方向考虑支持其他语言。
发展现状及路线图

AutoBE目前的开发阶段为 alpha 版本,并非所有功能都已完成。
首先,在构成瀑布模型的五个阶段中,实现代理尚未完成。因此,虽然可以通过该代理生成需求分析报告、设计数据库和API,并编写端到端测试代码AutoBE,但目前还无法实际实现API功能以完成应用程序。该实现代理目前正在开发中,计划于2025年8月31日随Beta版一同发布。
其次,AutoBE的提示符尚未优化。因此,虽然生成的代码AutoBE可以成功编译并正常运行,但可能并非用户真正想要的功能。
最后,AutoBE尚未开始 RAG 优化。因此,API 令牌消耗可能高于预期。基于 GPT-4.1 模型,生成一个包含 200 个 API 的后端应用程序大约需要 30 美元。未来通过 RAG 优化,这一成本将逐步降低。
结论
AutoBE它采用了与现有AI编码工具不同的方法。我们没有依赖基于文本的代码生成,而是将编译器技术与AI相结合,实现了结构安全的代码生成。
通过这种人工智能直接生成抽象语法树(AST)、编译器对其进行验证,并根据反馈生成完美代码的方法,我们实现了100%的编译成功率。这旨在从根本上提升软件开发的质量和稳定性,而不仅仅是增强便捷性。
目前该AutoBE项目仍处于 alpha 版本阶段,距离 beta 版本发布还需要进一步开发。不过,我们相信这种基于编译器的方法能够为开发者带来新的可能性。感谢各位对本AutoBE项目表现出的关注,也请大家继续关注我们的开发进展。
https://github.com/wrtnlabs/autobe
附录:AutoBE 与 AWS Kiro 的比较
AWS Kiro 是人工智能驱动型开发工具发展历程中的一个重要里程碑,尤其是在其 IDE 插件实现方面。在观察了 Kiro 作为集成开发环境扩展的方案后,我们认识到这种模式为开发人员的工作流程带来了巨大的价值。
Kiro 的 IDE 插件策略展示了 AI 编码助手如何无缝集成到现有开发环境中,在不中断既定工作流程的情况下提供实时帮助。这种集成模式使开发人员能够在熟悉的编码环境中直接利用 AI 功能,从而使该技术更易于上手,更便于日常使用。
受 Kiro 的 IDE 插件模式启发,我们计划AutoBE在 v1 版本发布时(预计于 2025 年底发布)同时开发并发布一款 IDE 插件。该插件将把AutoBEKiro 的瀑布式编译器系统直接集成到主流 IDE 中VSCode,使开发者能够:
- 通过熟悉的 IDE 界面生成后端应用程序
- 接收实时编译器反馈和验证
- 体验从需求分析到实施的完整开发周期
- 利用
AutoBE其现有开发环境中的 100% 编译成功保证
然而,我们必须承认,与 AWS Kiro 目前的发展成熟度和市场占有率相比,AutoBE我们的进展仍处于早期阶段。尽管我们基于编译器的方法和 100% 的构建成功率已取得了显著的技术里程碑,但 Kiro 已凭借其成熟的市场应用和强大的 IDE 集成能力,确立了自身作为一款综合解决方案的地位。
我们目前仍处于 alpha 测试阶段,实现代理仍在开发中,优化工作也尚未完成,这凸显了我们现有能力与 Kiro 成熟体验之间的差距。我们并不将此视为局限,而是将其视为深入学习 Kiro 的优势和成熟方法的良机。
我们致力于研究 Kiro 的成功策略,特别是其用户体验设计、IDE 集成模式和开发者工作流程优化。通过吸收他们的优势,并结合我们独特的基于编译器的架构和编译成功保证,我们旨在打造一个融合两种方法优势的卓越开源项目。
IDE 插件的开发将是让AutoBE开发者更容易上手的一个关键步骤,我们计划吸取 Kiro 实现中的经验教训,以确保我们提供一个完善、实用的解决方案,并通过我们的开源计划真正服务于开发者社区。