使用 Flask 将机器学习模型部署到 Heroku
本文将帮助您了解如何使用 Flask 在 Web 上部署机器学习模型。我使用Heroku部署了该机器学习模型。
Heroku是什么?
Heroku 是一个多语言云应用平台,使开发者能够部署、扩展和管理他们的应用程序。Heroku 简洁、灵活且易于使用,为开发者提供了一条最便捷的应用上市途径。Salesforce于2010 年收购了 Heroku,斥资 2.12 亿美元收购了这家云计算公司。
请按照以下步骤操作:
- 训练机器学习模型
- 使用 Flask 创建一个 Web 应用程序
- 将代码提交到 GitHub
- 将 GitHub 连接到 Heroku
- 部署模型
训练机器学习模型
我使用逻辑回归作为分类算法。我使用了弗雷明汉心脏研究数据集来预测患心脏病的风险。弗雷明汉研究的目标是研究心血管疾病(CVD)的发病率和患病率及其危险因素。
import pandas as pd
import numpy as np
import pickle
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# Reading dataframe and dropping rows with na values
data = pd.read_csv("framingham.csv")
data.dropna(inplace=True) # Consists 3658 records
# Computing Correlation
corr_matrix = data.corr().abs()
high_corr_var = np.where(corr_matrix > 0.35)
high_corr_var = [(corr_matrix.index[x], corr_matrix.columns[y]) for x, y in zip(*high_corr_var) if x != y and x < y]
"""
Variables to consider
age: Age of a person (Input a number)
smoker: Yes or No
Cigs per day: (Input a number)
diabaties: Yes or No
bmi: weight(Kg) and height(meters) calculate
BP: input a number
"""
def bmi(weight, height):
return round(float(weight) / (float(height) * float(height)), 2)
X_cols = ['male', 'age', 'currentSmoker', 'cigsPerDay', 'diabetes',
'sysBP', 'BMI']
Y_col = ['TenYearCHD']
X_vars = data[X_cols]
Y_var = data[Y_col]
# Renaming Columns
X_vars.columns = ['Gender', 'Age', 'Smoker', 'Cigarettes_Per_Day',
'Diabetic', 'BP', 'BMI']
Y_var.columns = ['Chances_of_hear_disease']
# Splitting data
X_train, X_test, y_train, y_test = train_test_split(X_vars, Y_var, test_size=0.25, random_state=0)
# Initiate the Model
logreg = LogisticRegression()
# fit the model with data
logreg.fit(X_train, y_train)
pickle.dump(logreg, open('model.pkl', 'wb'))
我使用了pickle库,它能将模型导出为字符流。这样做的目的是让这个字符流包含在另一个 Python 脚本中重建对象所需的所有信息。这将生成一个以字节写入模式显示的 model.pkl 文件,该文件稍后将用于部署模型。
使用 Flask 创建一个 Web 应用程序
下面我定义了应用路由并完成了 app.py 文件。我创建了一个Index.html 文件,它将作为首页,其中包含运行模型所需的所有字段。
第一步是设置一个密钥,用于确保客户端会话的安全。在 Flask 中使用会话时,需要创建一个由十六进制表示的随机字节组成的 secret_key。
# Set the secret key to some random bytes.
# Keep this really secret!
app.secret_key = b'_5#y2L"F4Q8z\n\xec]/'
Dataform 类定义了页面的结构,包括单选按钮、复选框和标签。这将有助于我们以正确的方式捕获数据。最后一步是渲染 index.html 模板并接收用户输入。当用户提交输入时,index 函数将被触发,应用程序将开始计算最终输出。
import os
import pickle
from flask_wtf import FlaskForm
from flask import Flask, render_template
from wtforms.validators import DataRequired
from wtforms import IntegerField, BooleanField, FloatField, SubmitField, RadioField
class Config(object):
SECRET_KEY = os.environ.get('SECRET_KEY') or 'you-will-never-guess'
APP_PATH = os.path.dirname(__file__)
app = Flask(__name__)
app.config.from_object(Config)
class DataForm(FlaskForm):
gender = RadioField('Gender', validators=[DataRequired()], choices=['Male', 'Female'])
age = IntegerField('Age', validators=[DataRequired()])
diabetic = BooleanField('Are you Diabetic?')
smoker = BooleanField('Do you smoke? ')
cig_count = FloatField('How many cigarettes do you smoke per day ?', default=0)
weight = FloatField('Weight (Kg)', validators=[DataRequired()])
height = FloatField('Height (cm)', validators=[DataRequired()])
bp = IntegerField('Blood Pressure (mmHg) Normal range : (90-120)/(60-80)', validators=[DataRequired()])
submit = SubmitField('Submit')
@app.route('/')
@app.route('/index', methods=['GET', 'POST'])
def index():
form = DataForm()
if form.validate_on_submit():
li = ['age', 'gender', 'cig_count', 'diabetic', 'height', 'weight', 'smoker', 'bp']
data = {}
for ele in li:
data[ele] = eval('form.' + ele + '.data')
gender = 1 if data['gender'] == 'Male' else 0
smoker = 1 if data['smoker'] else 0
diabetic = 1 if data['diabetic'] else 0
filename = os.path.join(app.config['APP_PATH'], 'model.pkl')
with open(filename, 'rb') as f:
model = pickle.load(f)
value = model.predict([[gender, data['age'], smoker, data['cig_count'],
diabetic, data['bp'], bmi(data['weight'], data['height'])]])
data = ['done', value[0]]
return render_template('index.html', value=data, form=form, data=data)
return render_template('/index.html', form=form)
def bmi(weight, height):
return round(float(weight) / (float(height / 100) * float(height / 100)), 2)
if __name__ == '__main__':
app.run(debug=True)
最重要的是创建 Procfile 和 requirements.txt 文件,它们负责配置模型,以便将其部署到 Heroku 服务器。web : gunicorn是固定的命令,之后第一个参数是 app.py 文件,即首先执行的文件。提供第一个参数时无需包含文件扩展名。第二个参数是 Flask 应用名称。requirements.txt
文件包含了需要在 Heroku 环境中安装的所有库。
web: gunicorn app:app

click==7.1.2
Flask==1.1.2
Flask-WTF==0.14.3
gunicorn==20.0.4
itsdangerous==1.1.0
Jinja2==2.11.2
joblib==0.16.0
MarkupSafe==1.1.1
numpy==1.19.1
pandas==1.1.0
python-dateutil==2.8.1
python-dotenv==0.14.0
pytz==2020.1
scikit-learn==0.23.2
scipy==1.5.2
six==1.15.0
sklearn==0.0
threadpoolctl==2.1.0
Werkzeug==1.0.1
WTForms==2.3.3
将您的代码提交到 GitHub 并将 Heroku 连接到 GitHub
在 Heroku 上创建一个应用名称,并按如下所示连接您的 GitHub 存储库。
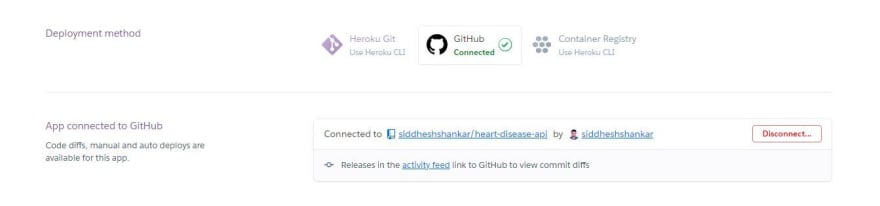
连接成功后,您可以通过两种方式部署应用:自动部署和手动部署。每次您向 GitHub 仓库提交任何内容时,都会自动进行自动部署,构建过程也会自动启动。我使用的是手动部署方式。只需选择
分支并点击部署按钮,构建过程就会开始。部署成功后,部署选项卡应如下所示:
最终应用程序
部署成功后,应用将被创建。点击查看,应用应该会打开。系统将生成一个新的URL。
来看看我的应用:https://heart-disease-predictor-api.herokuapp.com/
希望这篇文章对您有所帮助。这将帮助最终用户在无需任何外部依赖的情况下与我们的机器学习模型进行交互。
完毕!
Octocat 会带你到我的 GitHub 代码库……